The Differences Between Physical ERD vs Logical ERD
The target audience and purposes between physical ERD and logical ERD are different but they are dependent on one to another. Infact, logical ERD is helping to bridge between business user or functional team (business analyst, product owner or UI/UX designer) and technology implementor. Physical ERD must be created once the business team agree with the logical data model (logical ERD).
Below are differences between physical and logical ERD in various aspects
| Parameter | Logical ERD | Physical ERD |
|---|---|---|
| Main Focus | Defining high level business rule/entity interaction | Determine database system structure |
| Objectives | 1. aligning business needs or requirement with system design | 1. ensure data integrity 2. ensure no performance issue caused by database 3. ensure no technical constraint |
| Point of View | Capability Centric | System Centric |
| Format | Drawing Diagram | DDL (Data definition language) which is often done is SQL format |
| Element | Entities, Relationship, Attributes | Table, Foreign Key, Data Type, Referential Integrity, SQL DDL |
| Audience | Business user, functional team/business analyst | Database Engineer, Developer, Tech Lead, Solution Architect |
Converting Logical to Physical ERD Approach
Below are the step by step to convert following normalized (4nf) logical ERD to physical ERD
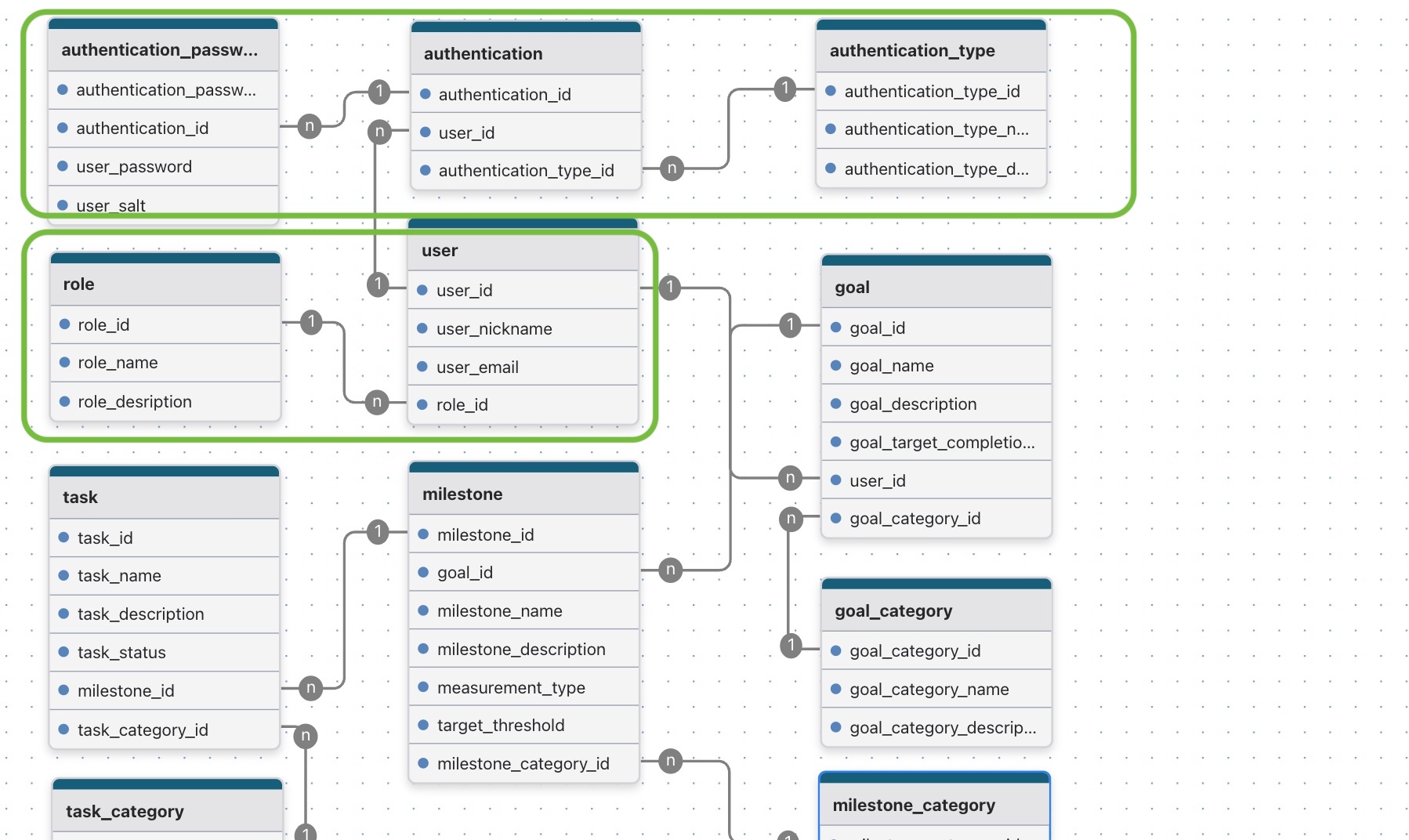 Milestoneku.com stage-0 logical ERD
Milestoneku.com stage-0 logical ERD
Domain and Entity Scoping
Depending on the agreed SDLC (softwre development life cycle) during the project, the approach to convert logical into physical ERD might be different. On waterfall scenario, all of the logical table will need to be converted into physical DDL (data definition language) where as on agile, usually the conversion will be done on several sprint. For example, on sprint one, only user and role domain are converter into physical ERD. Then, on 2nd sprint, the next domain will be picked up.
SDLC will impact the project execution results. Rigid waterfall process will ensure the ERD to be freezed at the beginning on the projects, making business user or functional team can’t revise the business logic at will. High chance that the end product will not satify the business.
In otherhand, on agile scenario, the physical and logical ERD might be revised every sprint. Technical team and business team will keep aligning the refining the ERD with actual business needs. Based on our experiences, ERD is a living collaborative document and should be driven by collaboration of business and technical team. It must be able to get updated to improve the quality of product as long as its feasible technically (not breaking the whole apps/server or causing major refactoring which require huge effort).
Below are the entity scope used on this article
- User
- Role
Identifying the Entity Attrbiute Data Type
Each of the entity attribute from the logical ERD need to be assigned into appropriate data type depending on the database type. For example, on postgresql database, below are the most common datatype used
- integer (4 bytes) - numeric without decimal
- text (unlimited text string, not recommended as there is no limit on the data length, increase the possibility to store junk data/unnecesary data that will eat up the storage).
- char - string with less than 10 length
- varchar - text with specific length
- boolean - store true or false
- date (not recommended, better to use timestamp as it easier to be converted into other timeformat or timezone)
- time (not recommended, same reasons like “date” format above)
- timestamp
- uuid - the absolute unique identifier. Modern database model/structure ditch auto increment and start to adopt uuid as auto increment number might be duplicated in distributed database scenario (rare case)
below are the list of attribute on each table with its own data type
Table: User
| Column | Data Type | Mandatory |
|---|---|---|
| user_id | UUID | yes |
| user_nickanme | varchar(100) | yes |
| user_email | varchar(255) | yes |
| role_id | UUID | yes |
Table: User
| Column | Data Type |
|---|---|
| role_id | UUID |
| role_name | varchar(100) |
| role_description | varchar(255) |
below is the DDL version on Postgresql format
CREATE TABLE roles (
role_id UUID DEFAULT gen_random_uuid(),
role_name VARCHAR(100) NOT NULL,
role_description VARCHAR(255)
);
CREATE TABLE users (
user_id UUID DEFAULT gen_random_uuid(),
user_nickname VARCHAR(100) NOT NULL,
user_email VARCHAR(255) NOT NULL UNIQUE,
role_id UUID NOT NULL,
);
Identifying The Primary key & Uniqueness
Primary key in relational database management system (RDBMS) referring to choosen column (or set of column) which can determine the row uniqueness. Primary key is often use surrogate key such as GUID (globally unique identifier)
below is the primary key for each table
| Table | Primary Key (PK) |
|---|---|
| user | user_id |
| role | role_id |
below is the DDL version on Postgresql format
CREATE TABLE roles (
role_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
role_name VARCHAR(100) NOT NULL,
role_description VARCHAR(255)
);
CREATE TABLE users (
user_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_nickname VARCHAR(100) NOT NULL,
user_email VARCHAR(255) NOT NULL UNIQUE,
role_id UUID NOT NULL,
);
Identifying the Relationship Between Tables and Foreign Key Candidates
Relationship between the tables are defined during the logical ERD creation. However, during the conversion from logical to physical ERD, those relationships need to be identified using foreign key.
Foreign key is a choosen column which idendicate the interlinkage between one table to another table
rule:
- if a table has foreign key, means those table is a parent table of one or more child table
- one parent table can have more than one child table
Below are the indentified relationship between role and user table including the foreign key candidatas
| Relationship | description | Source Table | Target Table | Foreign Key |
|---|---|---|---|---|
| one-to-many | 1. a role can have some user 2. user can only have one role |
role | user | user.role_id |
CREATE TABLE roles (
role_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
role_name VARCHAR(100) NOT NULL,
role_description VARCHAR(255)
);
CREATE TABLE users (
user_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_nickname VARCHAR(100) NOT NULL,
user_email VARCHAR(255) NOT NULL UNIQUE,
role_id UUID NOT NULL,
CONSTRAINT fk_role
FOREIGN KEY (role_id)
REFERENCES roles(role_id)
ON UPDATE RESTRICT
ON DELETE RESTRICT
);
Specifying the Referential Integrity Rules
Referential integrity is an enforced rules on RDBMS to ensure the data integrity. There are three main referential integrity rules on postgresql
- RESTRICT - role data can’t be deleted if there is a user who still use that role
- NO ACTION (default) - same with restrict but can be ignored until the end of SQL TRANSACTION
- CASCADE - if role data is deleted, then all user with that role will automatically get deleted.
Note: RE is also applied on the UPDATE scenario. RESTRICT means role_id can’t be updated until no user use that role_id. CASCADE means, if role_id is updated, all user.role_id that use the role_id will also get updated.
From the previous process, user.role_id has been identified as foreign key. a referential integrity cna be assigned to the foreign key.
| Foreign Key | ON DELETE | ON UPDATE |
|---|---|---|
| user.role_id | restrict | restrict |
it is recommended to set both ON DELETE and ON UPDATE referential integrity as restrict to ensure maximum data integrity on the databases.
below is the final DDL (data definition language) including RE as well as the previous steps process.
CREATE TABLE roles (
role_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
role_name VARCHAR(100) NOT NULL,
role_description VARCHAR(255)
);
CREATE TABLE users (
user_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_nickname VARCHAR(100) NOT NULL,
user_email VARCHAR(255) NOT NULL UNIQUE,
role_id UUID NOT NULL,
CONSTRAINT fk_role
FOREIGN KEY (role_id)
REFERENCES roles(role_id)
ON UPDATE RESTRICT
ON DELETE RESTRICT
);
above DDL can be executed using SQL command via postgresql shell or pgadmin.
