Pre-requsiite - Access to the repository
If the code repository is private and stored on github, read following article to authenticate from virtual machine into github private repositories
otherwise if the repo is on public, a normal git clone will do.
Project Structure
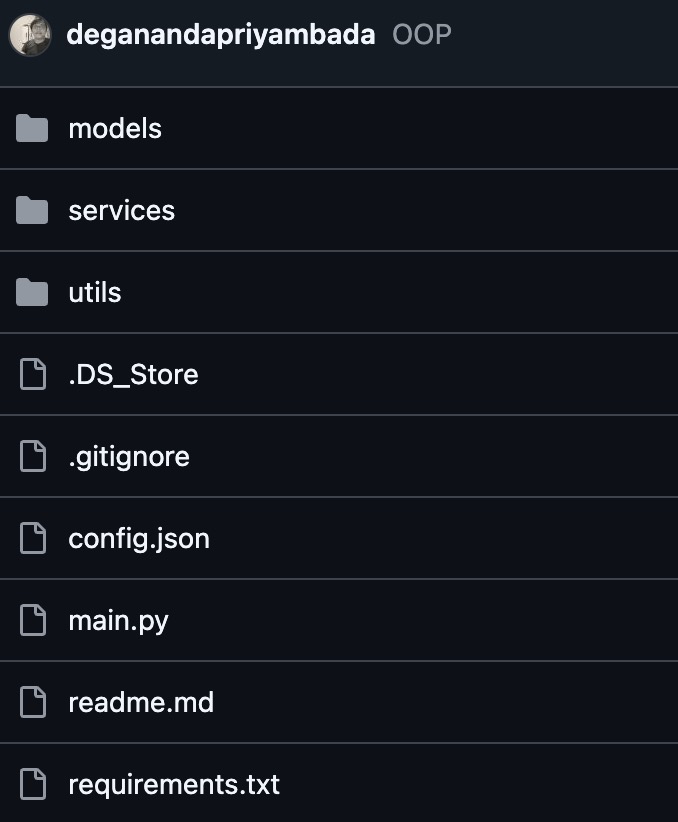 requirements.txt must be placed at project root folder
requirements.txt must be placed at project root folder
The existance of requirements.txt on the root project folder is a must. Playwright deployment from local machine to the virtual machine will utilize this file.
/requirements.txt
requirements.txt file is containing list of package dependencies as well as the version number. It should be generated during the development phases.
below is the content of requirements.txt
greenlet==3.2.4
playwright==1.56.0
pyee==13.0.0
setuptools==80.9.0
typing_extensions==4.15.0
wheel==0.45.1
Python Version
Different python version between local development machine and target virtual machine could lead into incompatability causing the playwright crawler can’t be executed.
check and ensure the local development python version and compare it with the one installed on virtual machine.
if using standard python
python --version
if using conda
conda env <env-name> activate
python --version
for ubuntu virtual machine, python3 is the default. hence, use following command to check python version installed on these ubuntu VM
python3 --version
Version comparison result between local development machine and target ubuntu VM
local machine
(pendar-crawler) deganandaferdian@degananda ~ % python --version
Python 3.12.12
ubuntu VM
root@pendar-spark:~/crawler/milestoneku-crawler# python3 --version
Python 3.12.3
root@pendar-spark:~/crawler/milestoneku-crawler#
a version mismatch is found, however, both of them are same 3.12 version, theoritically should be fine.
(optional) upgrade python sub version
upgrading sub version(3.12.x to 3.12.x) of python is generally recommended as it wont break the the whole depedencies, unlike upgrade version (eg: 3.12 to 3.14)
example command to upgrade python from 3.12.3 to 3.12.12 on ubuntu.
sudo apt update
sudo apt install python3.12
this will update 3.12 into latest sub version.
Install different version of python on ubuntu
Ubuntu server came with default python 3.12 on the machine.
root@pendar-spark:~/pyenvironment/crawler# which python3
/usr/bin/python3
It used by the APT, gnome, ubuntu internal script, etc. tools which are running by default on the ubuntu.
It also has some limited packages, following python package are not available out of the box:
- python venv
- python pip
- python building wheels
those packages are not installed to ensure the python3 (sym linked to python 3.12) used by ubuntu is kept to be minimal and light weight
— hence, it is recommended to install separate version of python312 (not symlink of python 3.12)
most safe and recommended way to install and manage multiple python version on ubuntu server(for production purpose) is to use pyenv.
it wont break the original python3 symlink used by ubuntu and keep the system light weight.
Install and Manage Multiple python environment for production server using pyenv
install pyenv
curl https://pyenv.run | bash
theoritically this will automatically install and configure the shell to access pyenv symlink/binary.
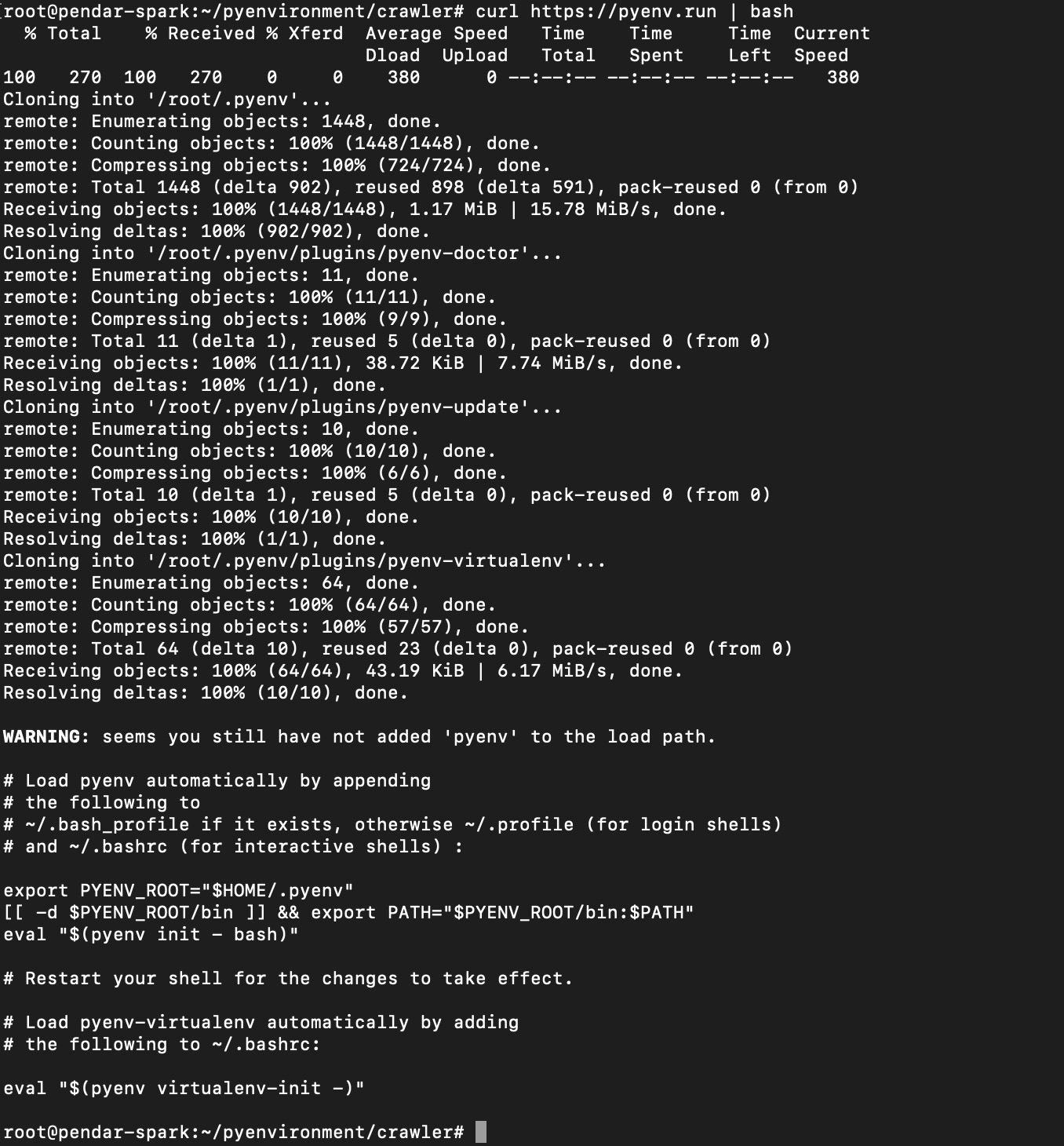 install pyenv on ubuntu server
install pyenv on ubuntu server
if pyenv can’t be executed from shell, then add it by using following command
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
note: execute the command line by line
restart bash
source ~/.bashrc
validate, by executing following command
pyenv --version
now if above command is called from shell, it should return the version number
 pyenv successfully installed on ubuntu server with proof of version number is shown on shell
pyenv successfully installed on ubuntu server with proof of version number is shown on shell
install build tools (dependency to install other python version, apart from the ubuntu default python) to avoid following error: no acceptable C compiler found
sudo apt update
sudo apt install -y build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm \
libncursesw5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev \
libffi-dev liblzma-dev
install specific python version (use same version based on development machine, on this cases is 3.12.12).
pyenv install 3.12.12
note: it might take a while depending on the server resources. On our cases with 2gigs of ram and 1 vCPU, it took +- 15 mins to compile and install python 3.12.12
root@pendar-spark:~/pyenvironment/crawler# pyenv install 3.12.12
Downloading Python-3.12.12.tar.xz...
-> https://www.python.org/ftp/python/3.12.12/Python-3.12.12.tar.xz
Installing Python-3.12.12...
Installed Python-3.12.12 to /root/.pyenv/versions/3.12.12
python version 3.12.12 successfully installed on pyenv environment.
Create virtual environment (baremetal python)
install python venv (not came as default on ubuntu server default python)
sudo apt install python3.12-venv
create a python virtual environment
python3 -m venv crawler
note: execute above command on folder which store all python virtual environment (centralized virtual environment directory) to have easy environment folder tracking.
mkdir ~/pyenvironment
cd ~/pyenvironment
python3 -m venv crawler
once the environment is created, go to that “crawler” directory
cd crawler
current active directory location
/root/pyenvironment/crawler
execute the command for creating python environment
python3 -m venv crawler
activate the python virtual environment on linux
source ./bin/activate
Create virtual environment (using pyenv)
— if alternate python version 3.12.12 is not yet created, following previous section to install it using pyenv.
use python 3.12.12 which install using pyenv locally on that specific user only
pyenv local 3.12.12
do not use global! it will break the original ubuntu python3(3.12) symlinks.
check if the python symlink is associated with pyenv
which python
check python version
python --version
it should return 3.12.12 on the console.
create virtual environment
python -m venev milestoneku-crawler
Install Playwright Project
install all required library from the requirements.txt
pip install -r requirements.txt
validate all the playwright packages is listed on pip
pip list | playwright
install playwright browser, following command will install all available browser (chromium, firefox and webkit)
first, install dependency needed for playwright on ubuntu to avoid getting this playwright error on ubuntu: Host system is missing dependencies to run browsers
sudo apt update
sudo apt install -y libgtk-3-0t64 libgbm1 libx11-xcb1 libxcb-dri3-0 \
libxcomposite1 libxdamage1 libxfixes3 libxrandr2 libasound2 \
libnss3 libdrm2 libatk1.0-0 libcups2 libxkbcommon0 \
libatspi2.0-0 libxshmfence1
then
playwright install-deps
begin the installation
playwright install
test run the script locally (depend on the project structure and configuration)
python main.py linkedin
below is the test result
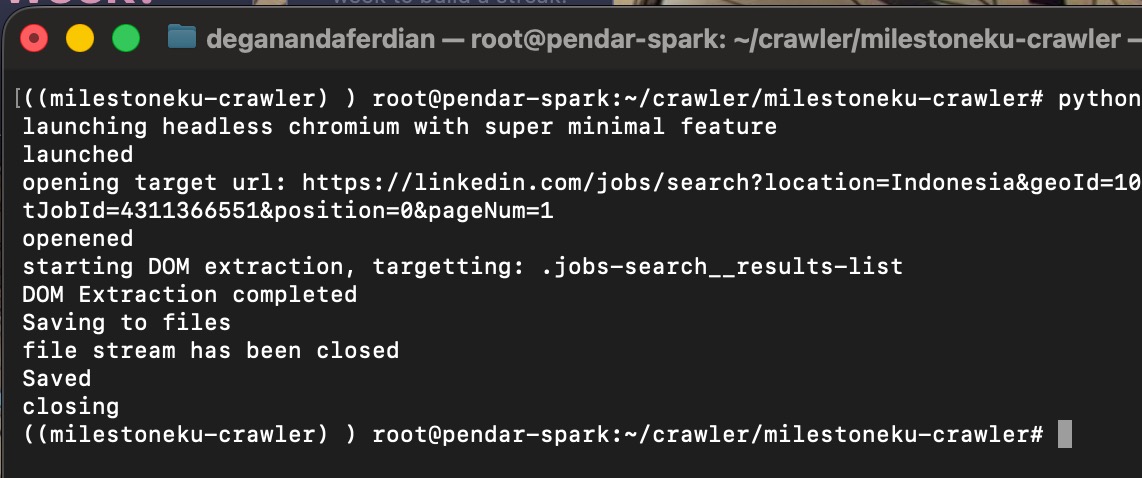 playwright with headless chromium is successfully launched
playwright with headless chromium is successfully launched
crawler successfully get the desired DOM
((milestoneku-crawler) ) root@pendar-spark:~/crawler/milestoneku-crawler/s_output# ls -la
total 168
drwxrwxr-x 2 root root 4096 Nov 30 05:40 .
drwxr-xr-x 7 root root 4096 Nov 30 05:40 ..
-rw-r--r-- 1 root root 161224 Nov 30 05:40 2025-11-30_linkedin
((milestoneku-crawler) ) root@pendar-spark:~/crawler/milestoneku-crawler/s_output#
Setting up Crontab
to schedule the crawler every min/hour/day, the cli command need to be added on the crontab.
unfortunately, crontab doesnt load the bash configuration, the activation of python virtual environment and execution of the python script need to be added into one shell script file as shown below
#!/bin/bash
# Load pyenv (cron does NOT load ~/.bashrc)
export PYENV_ROOT="/root/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
# Activate your venv
source /root/pyenvironment/milestoneku-crawler/bin/activate
# Run your script
python /root/crawler/milestoneku-crawler/main.py linkedin
add execution permission to the file
chmod +x linkedin-crawler.sh
to run the shellscript
/root/scripts/linkedin-crawler.sh
for example, below command will run the playwright crawler every 12 hours (hour 0, 12)
0 0,12 * * * /bin/bash /root/scripts/linkedin-crawler.sh >> /root/scripts/cron.log 2>&1
it is done!
Why not using docker/podman for playwright?
for specific scenario where the server resources is limited (like what we have at the moment is only 2 vCPU and 2 gigs of RAM), usage of docker will add memory overhead.
more over, those 2 gigs of ram will be shared with apache spark instances
if the production server doesnt have limited computing resources, it is recmmended to dockerized/containerized the playwright project to have better management and scaleability.
