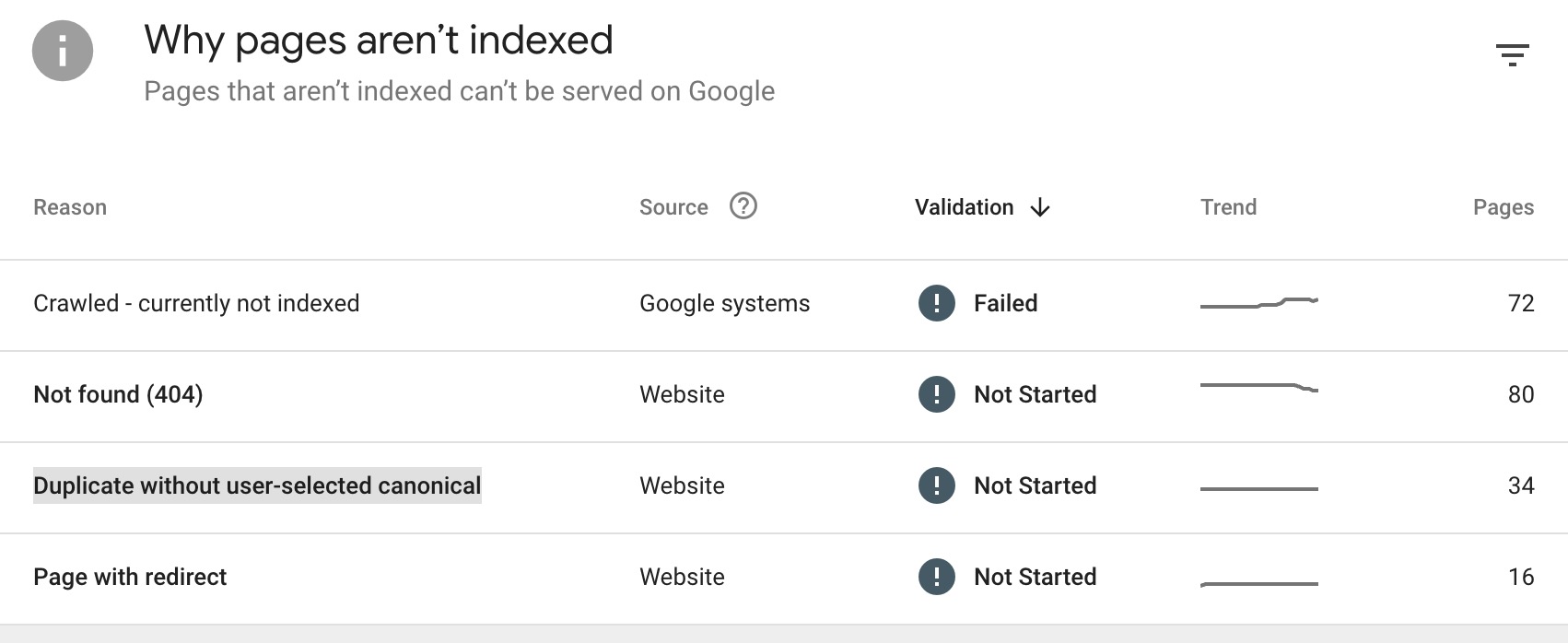
— Duplicated canonical issue is occured because one or multiplage page exist on the sites with identical content.
 Pipenpoof.com is encountering duplicated canonical issue on google search console
Pipenpoof.com is encountering duplicated canonical issue on google search console
Until the identical content is resolved, search engine will hold the indexing process.
Root Causes Analysis
Eventhough all the content is unique across multiple categories, duplicated canonical issue can happened due to following reasons:
- www and non www url are treated as different page
- different url path with identical content.
- canical tags are not set (not be an issue if #1st and #2nd problem has been addressed)
Identifying the Root Causes Findings
Each of the issues need to be addressed properly to completely resolve the duplicated canonical issues on google search console.
Addressing www and non-url url duplication
a website may be accessed through various way. Commonly accessed using FQDN (Fully qualified domain name) such as pipenpoof.com by entering those url on a browser.
Apart from that, a website can also be accessed using the server ip (internet protocol) address.
the varation of method to a website can cause search engine crawler to be confused as two identical content can coexist together on different page url.
for example, following article “Debugging Python Module Not Found On Conda Project” can be accessed through 3 different ways.
| No | Url | Content |
|---|---|---|
| 1 | https://pipenpoof.com/python/2025/08/Debugging-Python-Module-Not-Found-on-Conda-Project | Debugging Python Module Not Found On Conda Project |
| 2 | https://www.pipenpoof.com/python/2025/08/Debugging-Python-Module-Not-Found-on-Conda-Project | Debugging Python Module Not Found On Conda Project |
| 3 | https://master.dysiqo9435rfi.amplifyapp.com/python/2025/08/Debugging-Python-Module-Not-Found-on-Conda-Project | Debugging Python Module Not Found On Conda Project |
one additional access for pipepoof is through amplifyapp sub-domain as pipenpoof is hosted on top of AWS Amplify.
It need to be addressed immediatly to improve the SEO (Search engine optimization) ranking by pertaining the access flexibility but will be redirected to single url (https://pipenpoof.com ()
target routing table
| No | Source Url | Redirct Url |
|---|---|---|
| 1 | https://pipenpoof.com/python/2025/08/Debugging-Python-Module-Not-Found-on-Conda-Project | https://pipenpoof.com/python/2025/08/Debugging-Python-Module-Not-Found-on-Conda-Project |
| 2 | https://www.pipenpoof.com/python/2025/08/Debugging-Python-Module-Not-Found-on-Conda-Project | https://pipenpoof.com/python/2025/08/Debugging-Python-Module-Not-Found-on-Conda-Project |
| 3 | https://master.dysiqo9435rfi.amplifyapp.com/python/2025/08/Debugging-Python-Module-Not-Found-on-Conda-Project | https://pipenpoof.com/python/2025/08/Debugging-Python-Module-Not-Found-on-Conda-Project |
Set Single Canonical Tag for Identic Content on Different Url Path
Post is categorized based on two criteria which are categories and tags. For example, an article can both displayed under “java” categories and “spring” tags.
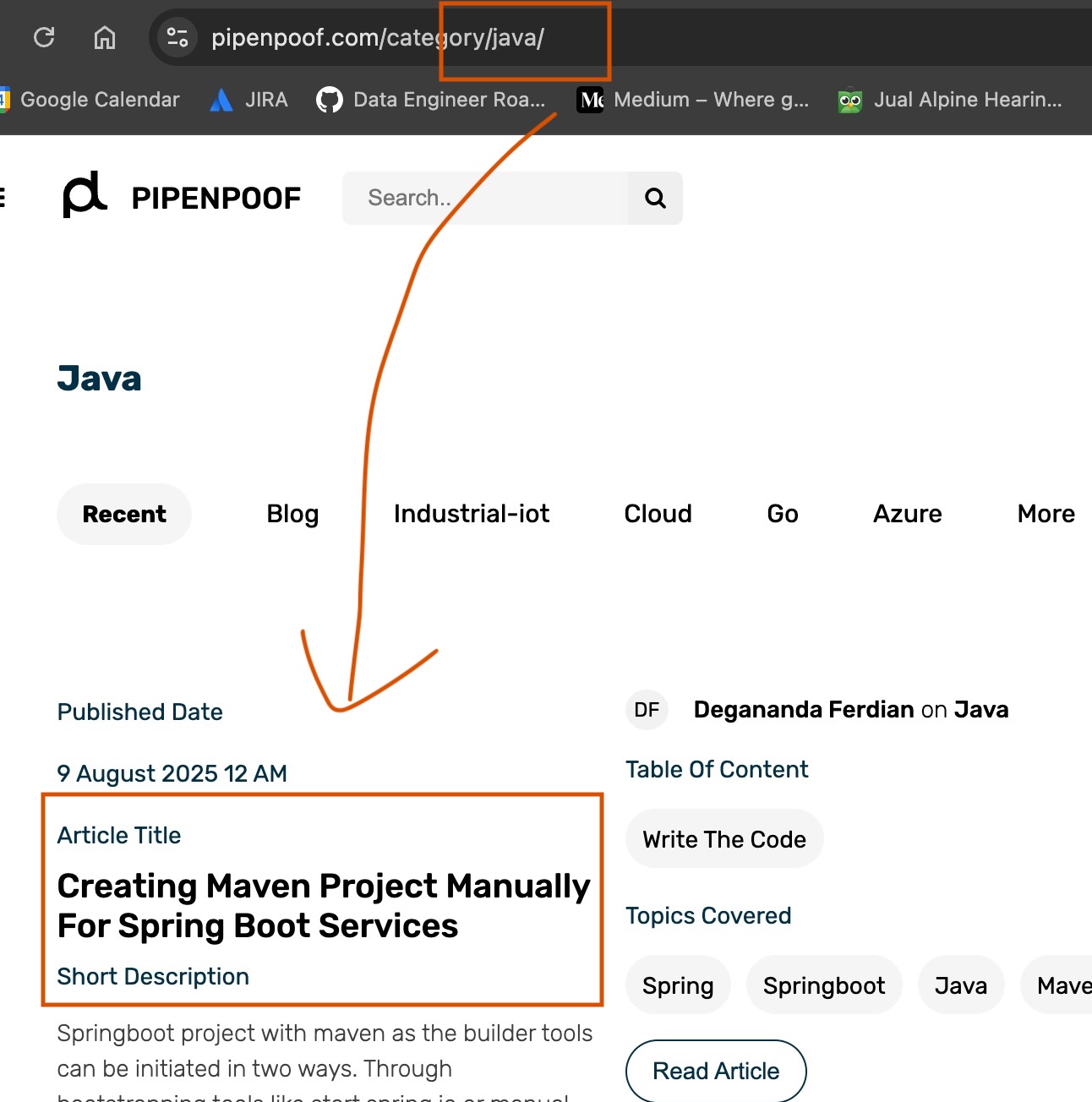 Article about initiating maven project displayed on Java category
Article about initiating maven project displayed on Java category
while the exactly same post also displayed on spring tags page.
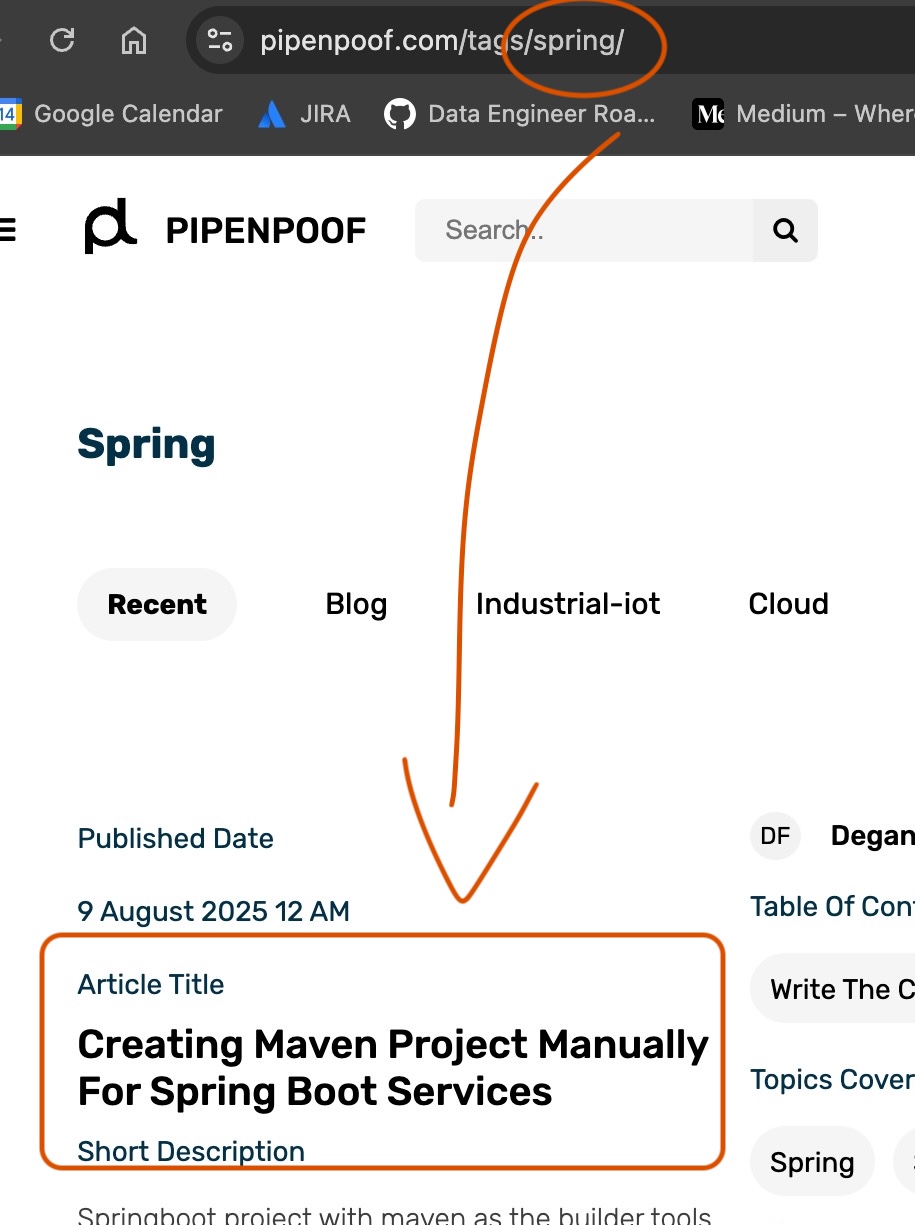 spring tags also has exactly same post as the article categorized by tags and categories
spring tags also has exactly same post as the article categorized by tags and categories
It causes search engine crawler to encounter two identical content eventhough both pagas has different categorization purposes.
— single canoical tags need to be set on either tags page or categories (need to choose one of it, the tags can’t be put on two different page)
Resolution
Below solution will be implemented on AWS Amplify as pipenpoof.com is deployed over there. The fix purposes regardless the hosting vendor, howoever, implementation side will be different dependent on the tech and deployment stack.
Route www to non wwww
go to aws console => custom domains module to find out the currely applied redirection logic
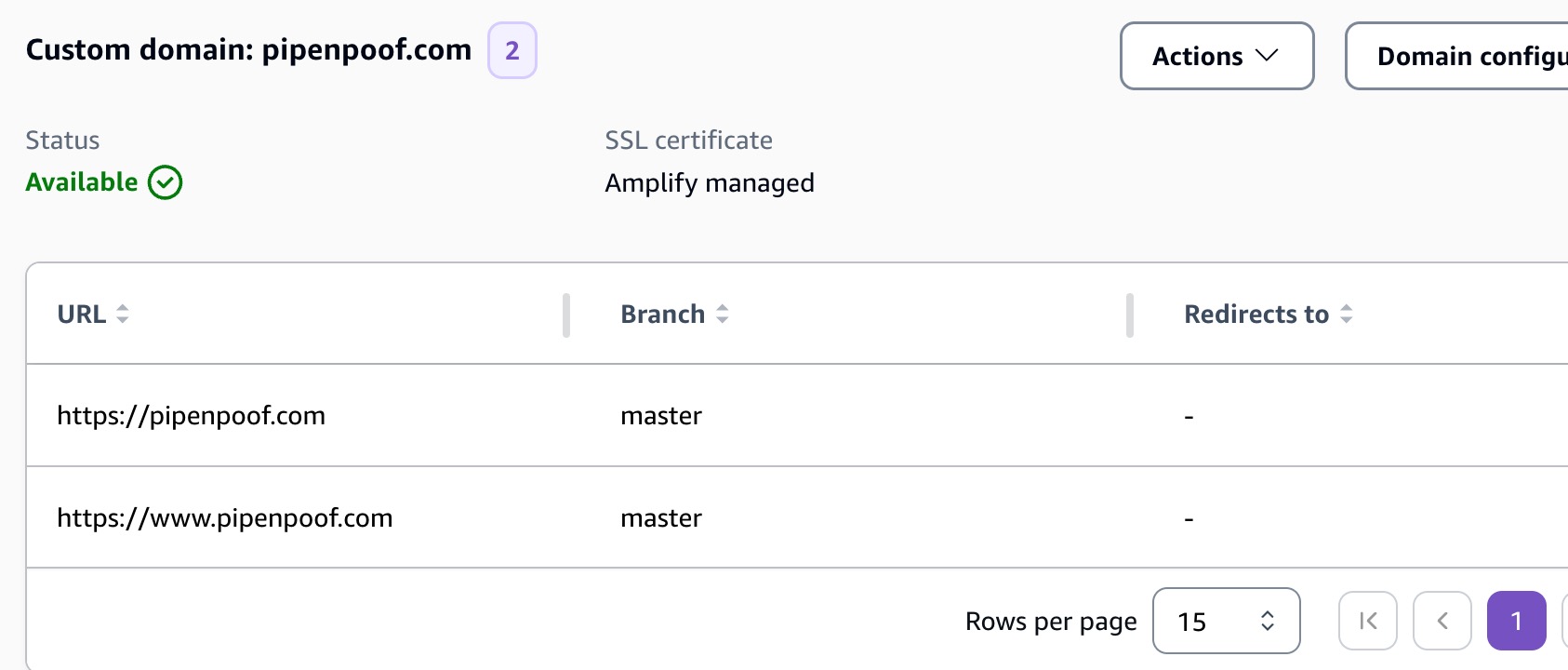 www and non www still treated as two different page url
www and non www still treated as two different page url
update the redirect config for www.pipenpoof.com to https://pipenpoof.com by adding following lines to the rewrites and redirect.
[
{
"source": "https://www.pipenpoof.com",
"status": "301",
"target": "https://pipenpoof.com"
},
{
"source": "/<*>",
"status": "404-200",
"target": "/index.html"
}
]
301 !== 302. 301 will permanently redirect the domain. Search engine crawler need 301 status to ensure the canonical.
above htaccess config on aws amplify will ensure all request sent to https://www.pipenpoof.com will be redirected to the https://pipenpoof.com
— dont forget to put the 302 rule as the first priority or line above the 404-200 rule.
because aws amplify will prioritize the first rule. If the /<*> rule set on the first priority it will override the redirect rule from www to non www.
disable master subdomain
all deployed code on aws amplify will have default subdomain under amplifyapp.com. this will also cause google search engine to be confused and triggering duplicated canonical issue.
[
{
"source": "https://www.pipenpoof.com",
"status": "301",
"target": "https://pipenpoof.com"
},
{
"source": "master.dysiqo9435rfi.amplifyapp.com",
"status": "301",
"target": "https://pipenpoof.com"
},
{
"source": "/<*>",
"status": "404-200",
"target": "/index.html"
}
]
default amplifyapp sub domain cannot be disabled. however, it can be redirected to the https://pipenpoof.com using same approach as before.
below is the final rewrite rule on aws amplify
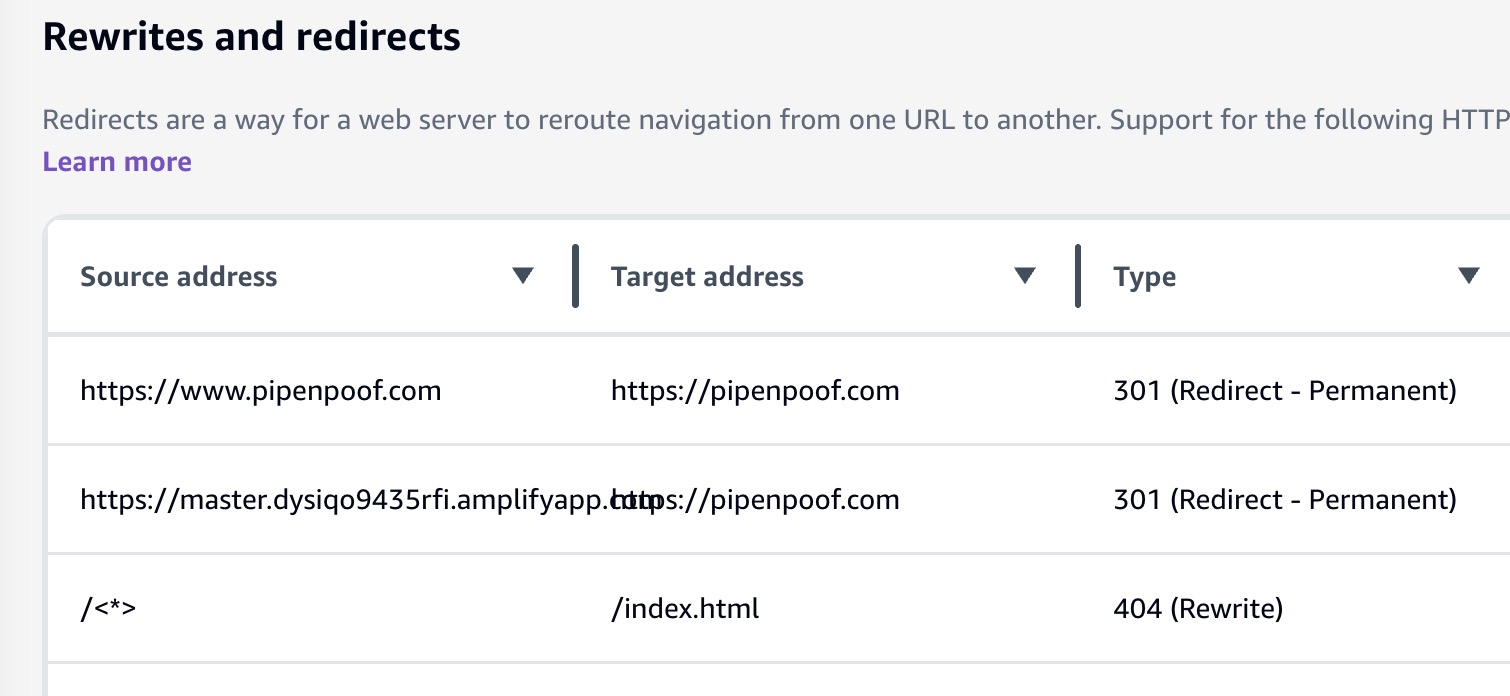 rewrite rule to redirect www, amplifyapp to non www main domain
rewrite rule to redirect www, amplifyapp to non www main domain
Adjust Route 53 DNS Config
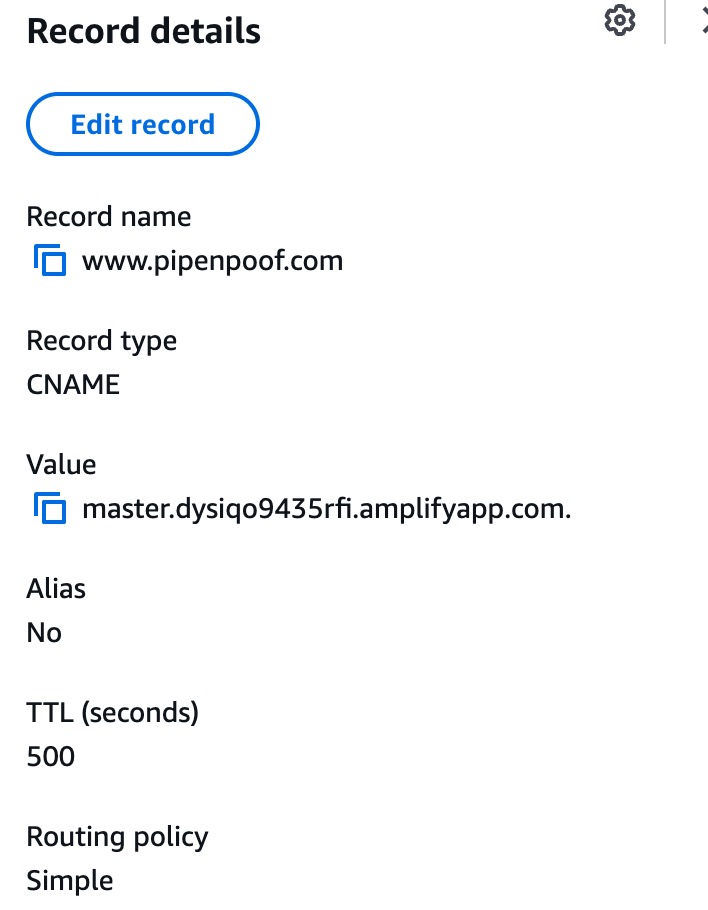 www CNAME config remapped to aws-amplify server
www CNAME config remapped to aws-amplify server
ensure the www.pipenpoof.com (www of the site main domain name) CNAME config is present and pointed to the server hostname instead of to the cache server(eg: cloudfront)
Testing
Curl can be used to test whether the rule is successfully applied or not using following command
curl -I https://www.pipenpoof.com
curl -I https://master.dysiqo9435rfi.amplifyapp.com
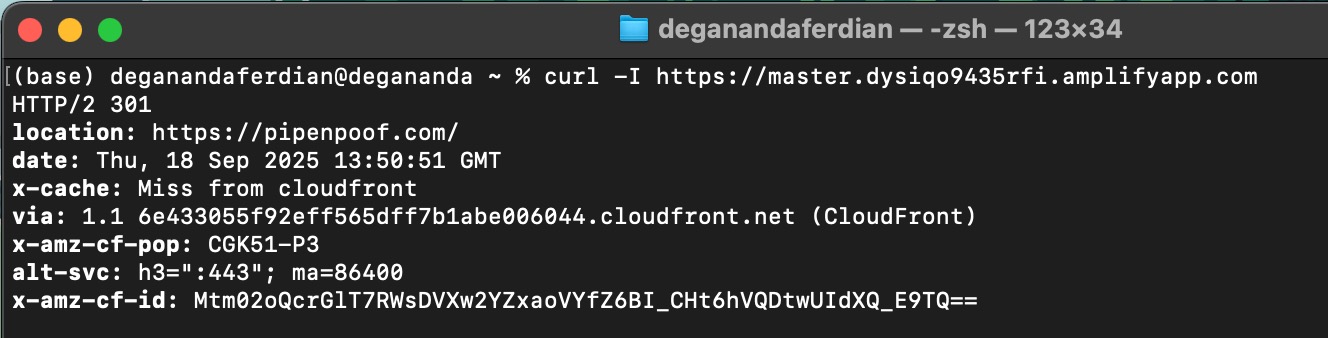 amplifyapp redirected to the main pipenpoof.com
amplifyapp redirected to the main pipenpoof.com
Look for the http header 301 (redirect status) on the console
its better to use tools such as httpstatus.io to check the url canonical.
 pipenpoof.com canonical url check
pipenpoof.com canonical url check
from above images, all url except the non url (https://pipenpoof.com) are redirected (301)
add canonical link on tags page
example on following spring tags page
https://pipenpoof.com/tags/springboot/
it has similar content with “java” catagory page
https://pipenpoof.com/category/java/
hence below cnonical tags need to be put on https://pipenpoof.com/tags/springboot/ pages header. pringboot tags is the child of java categories.
<link rel="canonical" href="https://pipenpoof.com/category/java">
below is the canonical config business rules
| No | Path | Canonical Url |
|---|---|---|
| 1 | / | https://pipenpoof.com/ |
| 2 | /tags/ |
https://pipenpoof.com/category/ |
| 3 | /category/ |
https://pipenpoof.com/category/ |
| 4 | /search/?=<search_value | none canonical url and set no indexs on robots |
| 5 | other/any | page.site + page.url |
above rule is translated into jekyll liquid syntax
<link rel="canonical" href="https://pipenpoof.com/jekyll/2025/09/Fixing-Google-Search-Console-Issues-Duplicate-without-User-Selected-Canonical">
application on non jekyll projects can be different, but the goal is the same. Each page on the sites need to have single unique canonical url except the search page.
Set no index on search page
search page doesnt have any unique content eventhough the result is dynamic.
it is suggested to put robots no follow to ensure the crawler not checking the search page.
<meta name="robots" content="noindex, follow">
above line of code will tell the search engine crawler to not crawl and index the page.
