Jupyter notebook can be integrated with apache spark master node. The UI will be useful to wrote and run the python script as well as submit the job into spark worker node.
— eventhough jupyter notebook is not mandatory tools for apache spark setup, it is definitely the industry standard to have collaborative UI for working on the python projects.
Preparation
first thing to check is the network connectivity. Ensure the spark master and worker node is bind to the server actual ip (internet protocol) address.
usually private ip is used as the jupyter notebook and apache spark are never intended to be accessible from the public.
Network Connectivity Check
there are two provisioned virtual machine on this setup with following details
- VM 2 (1 vCPU and 2 gb vRAM) - to host the apache spark single node cluter (one master and one worker).
- VM 1 (1 vCPU and 1 gb vRAM) - to host jupyter notebook, python3 and postgresql(for iceberg REST catalog)
note: both VM are hosted on digital ocean droplet. Network configuration might be slighly differ on different cloud provider.
both of the vm has been placed into single one virtual network(or can also be called as VPC).
| VM | Private IP | Usages |
|---|---|---|
| VM 1 | 10.130.0.3 | Postgresql, Jupyter Notebook |
| VM 2 | 10.130.0.4 | Spark Single Node |
ensure both of the VM can communicate.
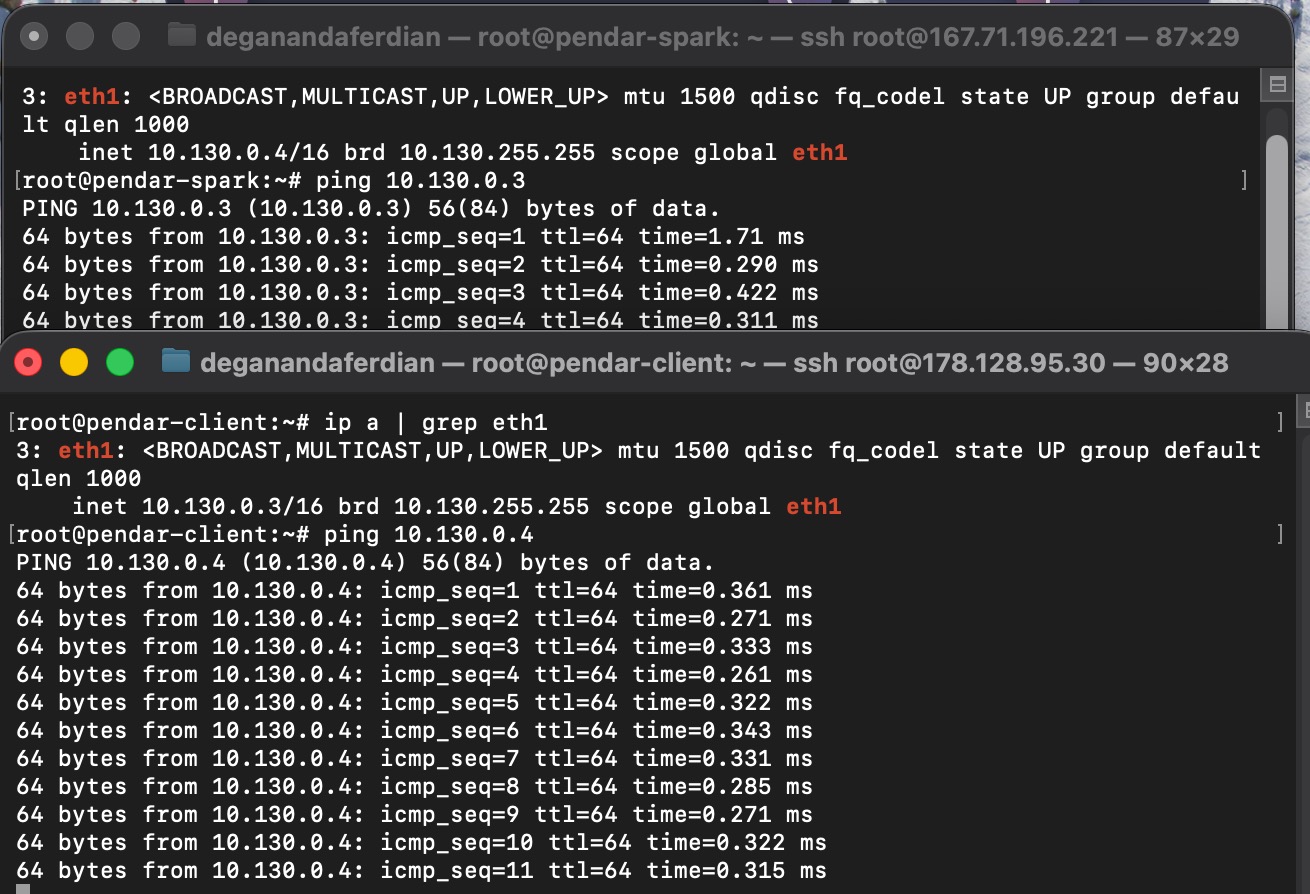 both VM1 and Vm2 can communicate with each other through ping(in this case it is not blocked.)
both VM1 and Vm2 can communicate with each other through ping(in this case it is not blocked.)
*ping can be use to test if these method is not blocked.
if ping is blocked, can try to use telnet on port 5432 (postgre’s default port) and ensure these port are open.
Bind Apache Spark to Correct Private IP
by default, apache spark is not configured on the correct network interfaces.
on this cases, the apache spark is still binded to the eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
inet 10.15.0.5/16 brd 10.15.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8d3:39ff:fe3a:cec4/64 scope link
valid_lft forever preferred_lft forever
it is supposed to be bind to following ip 10.130.0.4
ssh to the VM#2 and update the spark conf which is located on following path using nano or vim
nano /opt/spark/conf/spark-env.sh
after fresh install of apache spark, by defaul the spark-env.sh is not exist. the nano command will create a new file if thoese file name is not yet exist.
add the proper private ip on the following lines.
SPARK_LOCAL_IP=10.130.0.4
SPARK_MASTER_HOST=10.130.0.4
SPARK_WORKER_HOST=10.130.0.4
save the files by pressing ctrl + O
Restart the spark master and spark node
once the spark-env has been configured to bind the actual private ip, execute following command
stop both spark master node and worker node
/opt/spark/sbin/stop-all.sh
in case the stop-all.sh is not working, stop both master and worker node manually
/opt/spark/sbin/stop-master.sh
/opt/spark/sbin/stop-worker.sh
validate on JPS and ensure master and worker are not listed
root@pendar-spark:/opt/spark/sbin# jps
98854 Jps
root@pendar-spark:/opt/spark/sbin#
start spark master node
/opt/spark/sbin/start-master.sh
start spark worker node and set the correct hostname for the maste spark node.
/opt/spark/sbin/start-worker.sh spark://10.130.0.4:7077
check on the jps command, ensure both master and worker node are listed
root@pendar-spark:/opt/spark/sbin# /opt/spark/sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-pendar-spark.out
root@pendar-spark:/opt/spark/sbin# /opt/spark/sbin/start-worker.sh spark://pendar-spark:7077
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-pendar-spark.out
root@pendar-spark:/opt/spark/sbin# jps
98882 Master
98935 Worker
98985 Jps
root@pendar-spark:/opt/spark/sbin#
Validate
open the spark logs and ensure both master and worker already bind to the private ip
master node status
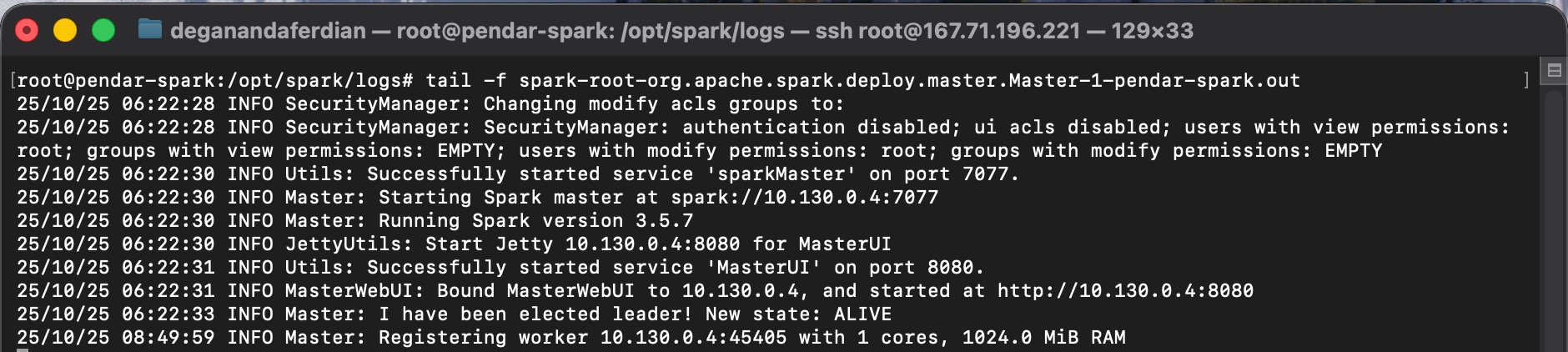 spark master worker is running and binded to private ip
spark master worker is running and binded to private ip
worker node status
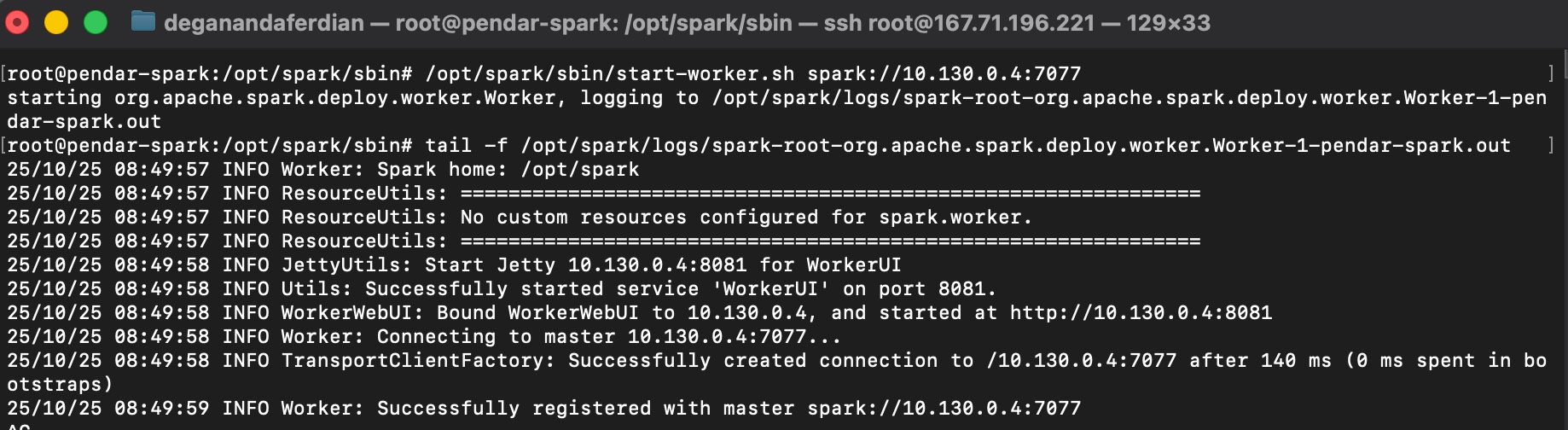 spark master worker is running and binded to private ip
spark master worker is running and binded to private ip
Install Jupyter Notebook on the VM 1
main rule of thumb to integrate pyspark into apache spark: both of the pyspark within the same python environment of jupyer notebook and apache spark should have same version.
check apache spark version
/opt/spark/bin/spark-submit --version
example output
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.7
/_/
Using Scala version 2.12.18, OpenJDK 64-Bit Server VM, 17.0.16
from above output, it shown that the apache spark version is 3.5.7
Install pip
by default ubuntu server 24.04 already has python 3 installed (version 3.12). However, it doesnt have pip(package management of python) installed yet.
install pip using following command:
update the apt package manager
apt update
install pip via apt and install python3 (incase it is not yet installed)
apt install -y python3 python3-pip
validate if the pip has been installed.
pip --version
should return the pip version.
root@pendar-client:~# pip --version
pip 24.0 from /usr/lib/python3/dist-packages/pip (python 3.12)
root@pendar-client:~#
Create virtual environment
it is recommended to create virtual environment for the jupyter notebook. so it wont conflicting with the host python.
install python3 venv
apt install python3.12-venv
create python virtual environment
sudo python3 -m venv projectmakaryo
expected output
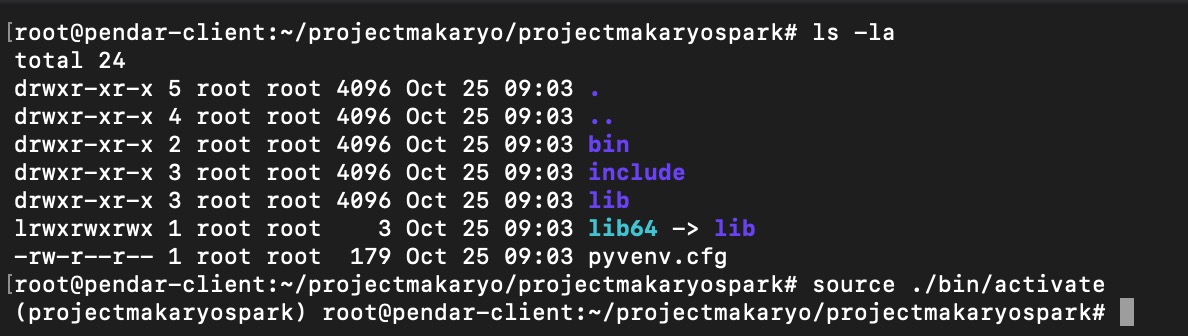 newly created python virtual environment
newly created python virtual environment
root@pendar-client:~/projectmakaryo/projectmakaryospark# ls -la
total 24
drwxr-xr-x 5 root root 4096 Oct 25 09:03 .
drwxr-xr-x 4 root root 4096 Oct 25 09:03 ..
drwxr-xr-x 2 root root 4096 Oct 25 09:03 bin
drwxr-xr-x 3 root root 4096 Oct 25 09:03 include
drwxr-xr-x 3 root root 4096 Oct 25 09:03 lib
lrwxrwxrwx 1 root root 3 Oct 25 09:03 lib64 -> lib
-rw-r--r-- 1 root root 179 Oct 25 09:03 pyvenv.cfg
root@pendar-client:~/projectmakaryo/projectmakaryospark#
activate the environment
source ./bin/activate
if the activation of environment variable is success, a new prefix will be added on the shell as shown below
Install Jupyter Notebook and pyspark
as mentioned on previous section, apache spark version used on this article is version 3.5.7, hence the pyspark version should follow the same.
execute following command to install pyspark and jupyter notebook
pip3 install pyspark==3.5.7 jupyter
note: just be safe, ensure the pip3 is pointed to the python binary on the virtual environment.
which pip3
validate if pyspark and jupyter has been installed properly
pip3 list
Connectivity test from VM1 to VM2
ensure the jupyter vm (VM1) can connect into VM2 (apache spark VM) especially on port 7077
execute following telnet command
telnet 10.130.0.4 7077
expected output
(projectmakaryospark) root@pendar-client:~/projectmakaryo/projectmakaryospark# telnet 10.130.0.4 7077
Trying 10.130.0.4...
Connected to 10.130.0.4.
as shown on above response, vm2 can already connect to port 7077 of vm1
Start jupyter
excute following command to start the jupyter and expose the UI
jupyter notebook --ip=0.0.0.0 --port=8888 --no-browser --allow-root
it will automatically opened a browser.
 jupyter notebook require token as authorization proof
jupyter notebook require token as authorization proof
input the token which can be seen on the console.
Hello world test
 Hello World from jupyter notebook!
Hello World from jupyter notebook!
try to create an ipynb files and write hello world script.
print("Hello World")
ensure it can compile and run the python script
Install JDK
pyspark require JVM in order to be able to submit the job into apache spark worker.
sudo apt install openjdk-17-jdk -y
validate
java --version
should return the installed java version
(projectmakaryospark) root@pendar-client:~/projectmakaryo/projectmakaryospark# java --version
openjdk 17.0.16 2025-07-15
OpenJDK Runtime Environment (build 17.0.16+8-Ubuntu-0ubuntu124.04.1)
OpenJDK 64-Bit Server VM (build 17.0.16+8-Ubuntu-0ubuntu124.04.1, mixed mode, sharing)
get java installation folder
sudo update-alternatives --config java
sample output
* 0 /usr/lib/jvm/java-17-openjdk-amd64/bin/java 1711 auto mode
1 /usr/lib/jvm/java-17-openjdk-amd64/bin/java 1711 manual mode
update environment variable
echo 'export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64' >> ~/.bashrc
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> ~/.bashrc
source ~/.bashrc
Submit job to apache spark worker.
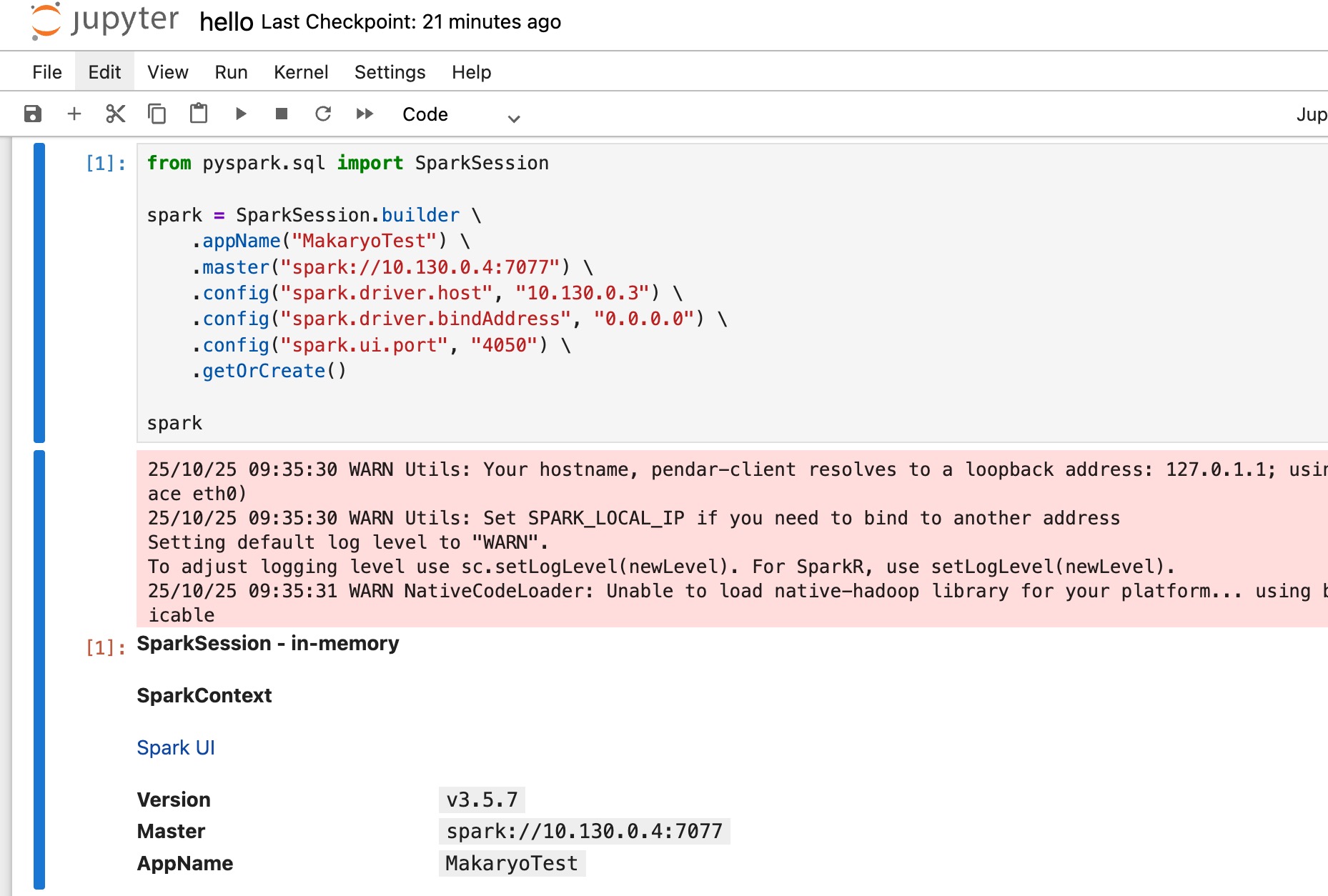 create spark session and register application to worker
create spark session and register application to worker
add this to the ipynb
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("MakaryoTest") \
.master("spark://10.130.0.4:7077")
.config("spark.driver.host", "XXXXXX")
.config("spark.driver.bindAddress", "0.0.0.0") \
.config("spark.ui.port", "4050") \
.getOrCreate()
spark
replace the spark.driver.host value with the private ip of the jupyter vm (in this case is 10.130.0.3).
done! — if, jupyter vm can connect with the spark worker node, the new application called ‘makaryoTest’ will be registered on spark worker.
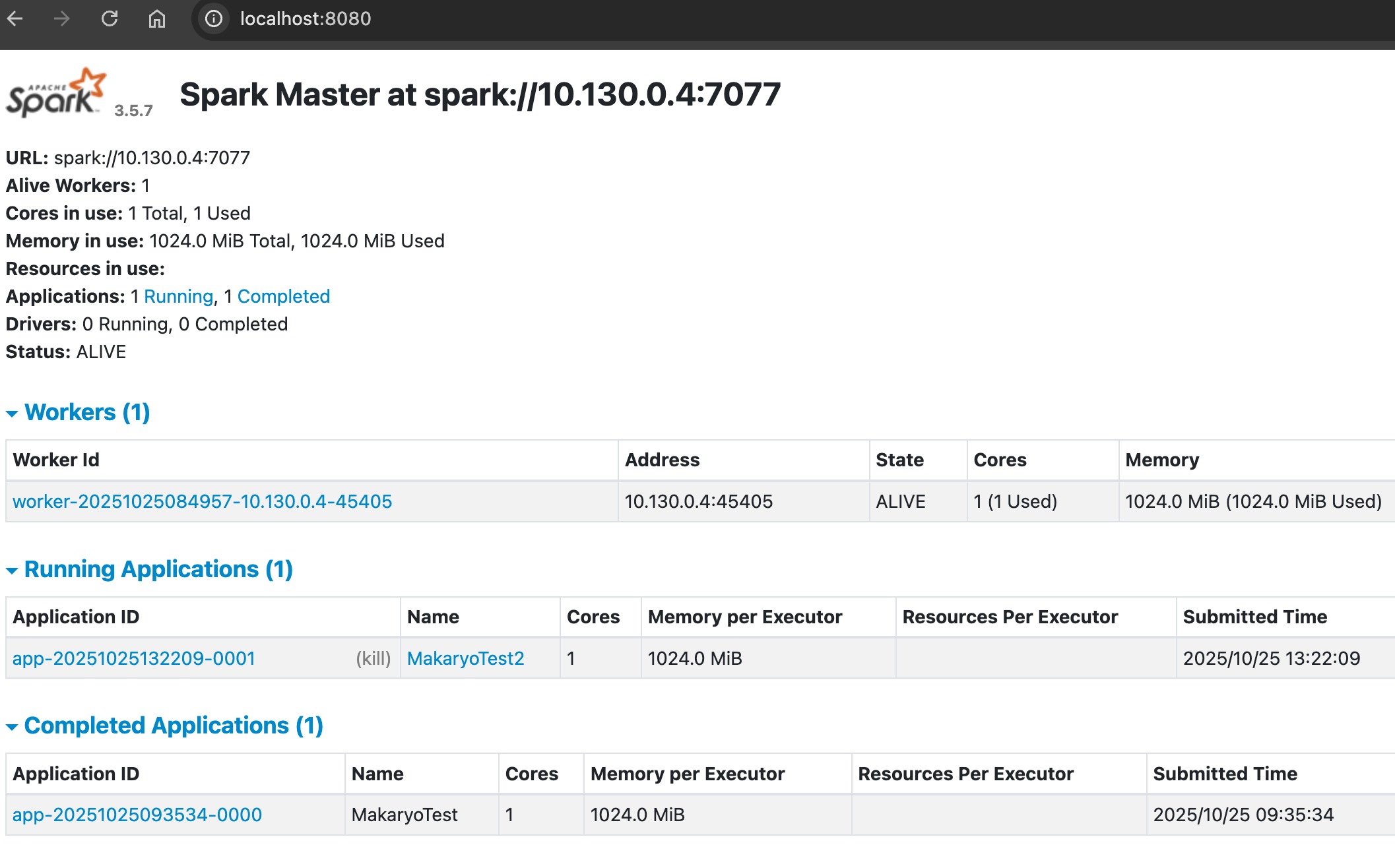
job details can be monitored on the spark ui:jobs as shown below
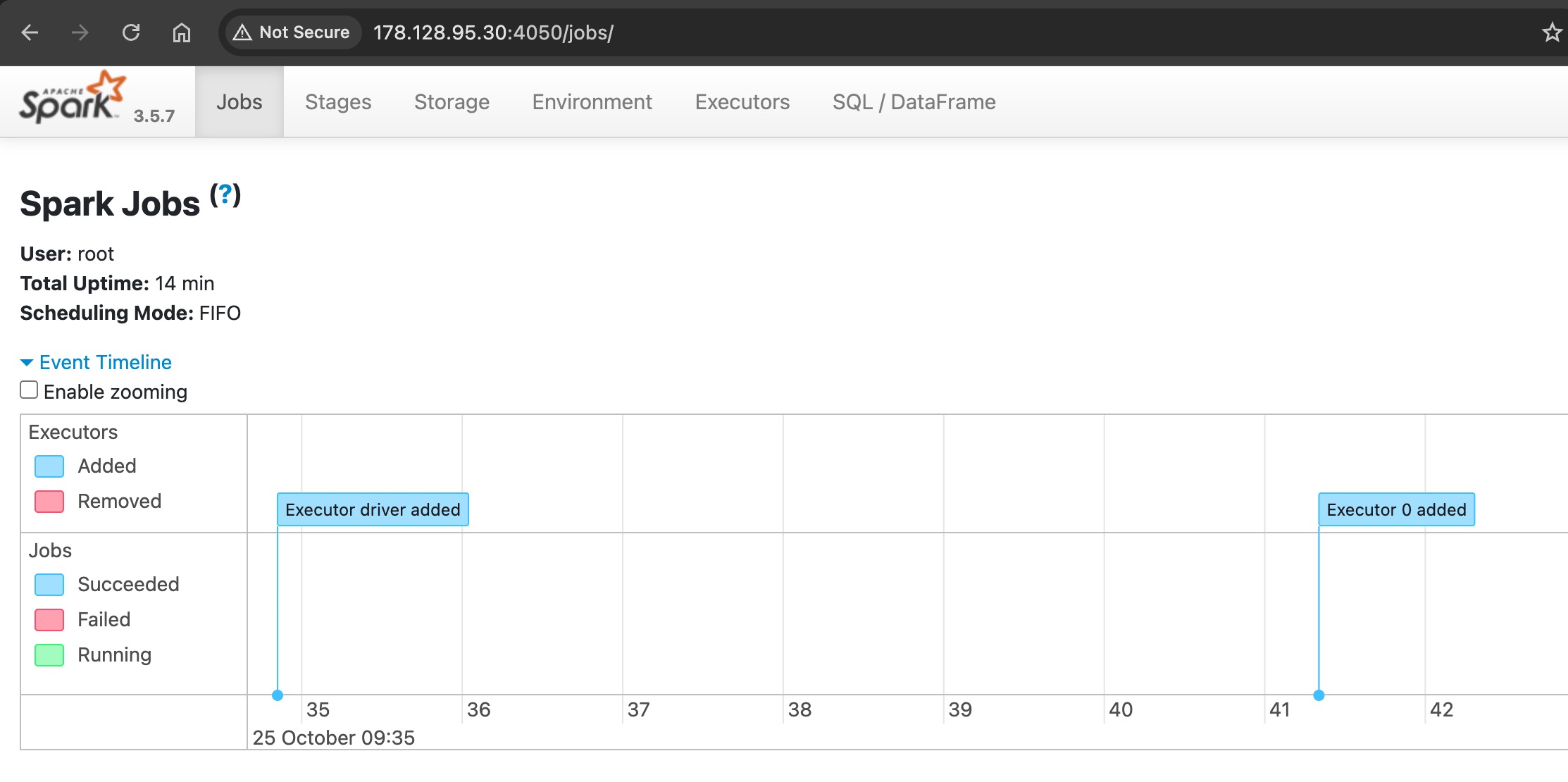 spark ui to check the job status
spark ui to check the job status
Additional Information
since the spark UI is binded through private ip, the exposed port(8080) can only be accessed using VPN(virtual private network).
however, provisioning a vpn server is one additional price.
there is work around(should not be used for production) by using ssh tunneling
 port forwarding using ssh tunneling to access the private url of spark ui
port forwarding using ssh tunneling to access the private url of spark ui
execute following command
ssh -L 8080:10.130.0.4:8080 root@<public_ip_of_spark_server>
it will forward the local spark ip(10.130.0.4:8080) to the client’s localhost.
