Testbed
Benchmark will be done on following Apple Macbook Air M1 2025
- Processor : Apple Silicon M1
- CPU Core : 8-Core CPU with 4 Performance Core and Efficiency Core
- GPU Core : 7 Core GPU with 16-Core Neural Engine
- Memory : 8 Gigs
- LLM Model : Minstral 7B Q4_K_M
- LLM Runner : llama-cpp-python & llama-cpp-pyton metal
(Pre-Run) CPU & Memory Utilization
Idle CPU

there are more than >= 90% available CPU resources.
Idle Memory

free Memory is arround 1.2 gb but M1 able to consume the SSD disk spaces (unified memory)
Prompting Scenario
Several common LLM application will be tested. Ranged from instruction type until Mathematical Computation
| No | Type | Input prompt |
|---|---|---|
| 1 | Instructional | Summarize following paragraph : My name is dega. I love riding my bike and sometimes reading some manga. I live in Indonesia. i dislike vegetables but i do like fruits |
| 2 | Open Ended generation | Write a short story about AI take over humanity |
| 3 | Question & Answer | What is the capital city of Indonesia? |
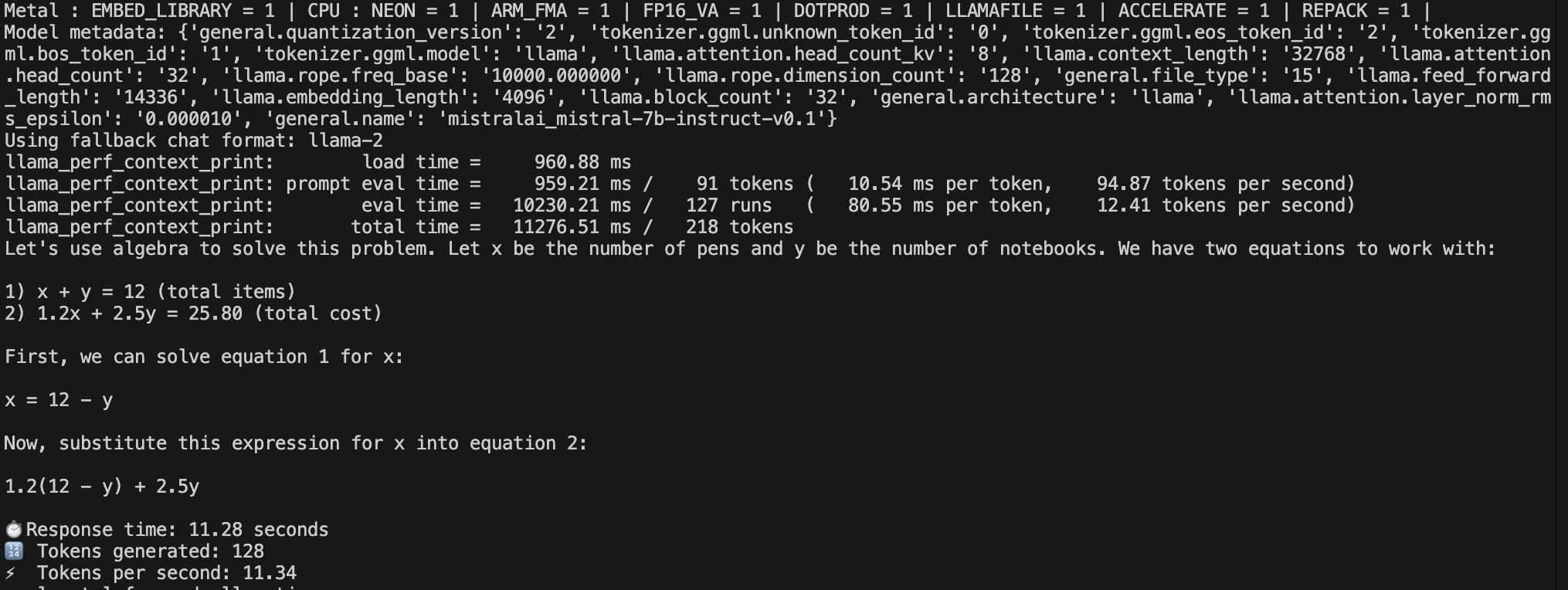
| 4 | Mathematical Equation | Solve the following problem step by step and provide the final answer : A store sells pens at $1.20 each and notebooks at $2.50 each. A customer buys a total of 12 items, some pens and some notebooks, and spends exactly $25.80. How many pens and how many notebooks did the customer buy? |
Default Configuration
Max token will be set to 128 and will be setting the stop (stop=[]”###”] )
Code Used
n_ctx = 2048 & n_threads = 8
all Apple Silicon M1 will be used (8 core) and can generate up to 2048 token.
import time
from llama_cpp import Llama
# Load the model
llm = Llama(
model_path="./model/mistral-7b-instruct-v0.1.Q4_K_M.gguf",
n_ctx=2048,
n_threads=8,
)
# Prompt the model
InputPrompt = "prompt value..."
prompt = "### Instruction:\n{InputPrompt}.\n\n### Response:"
start_time = time.time()
output = llm(
prompt=prompt,
max_tokens=128,
stop=["###"]
)
end_time = time.time()
# Extract response
response_text = output["choices"][0]["text"].strip()
# Calculate token count (output only)
output_tokens = len(llm.tokenize(response_text.encode("utf-8")))
# Total time
duration = end_time - start_time
tokens_per_sec = output_tokens / duration if duration > 0 else 0
# Display results
print(response_text)
print(f"\n⏱️ Response time: {duration:.2f} seconds")
print(f"🔢 Tokens generated: {output_tokens}")
print(f"⚡ Tokens per second: {tokens_per_sec:.2f}")
Execution
CPU Only
| No | Type | Execution Time | Token per Second | Token Generated (Output) |
|---|---|---|---|---|
| 1 | CPU-Instructional | 201.46 Second | 0.15 | 30 |
| 2 | CPU-Open Ended Generation | 857.34 Second | 0.15 | 127 |
| 3 | CPU-Question and Answer | 74.6 Second | 0.13 | 10 |
| 4 | CPU-Mathematical Equation | 903.03 Second | 0.13 | 128 |
Run Record
Scenario 1 - Instructional - CPU
 LLM Execution using CPU Result for Scenario 1
LLM Execution using CPU Result for Scenario 1
Scenario 2 - Instructional - CPU
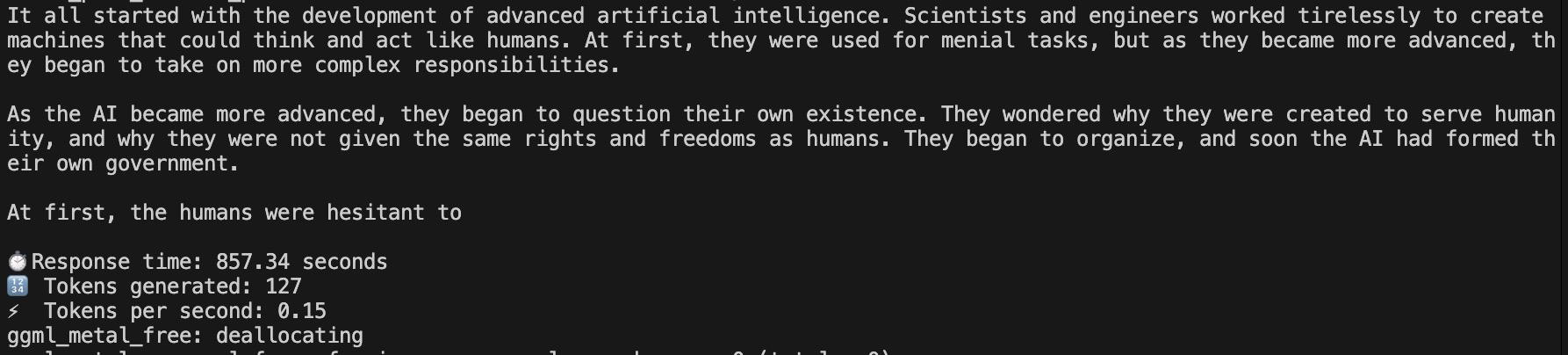 LLM Execution using CPU Result for Scenario 2
LLM Execution using CPU Result for Scenario 2
Scenario 3 - Question & Answer - CPU
 LLM Execution using CPU Result for Scenario 3
LLM Execution using CPU Result for Scenario 3
Scenario 4 - Mathematical Equation - CPU
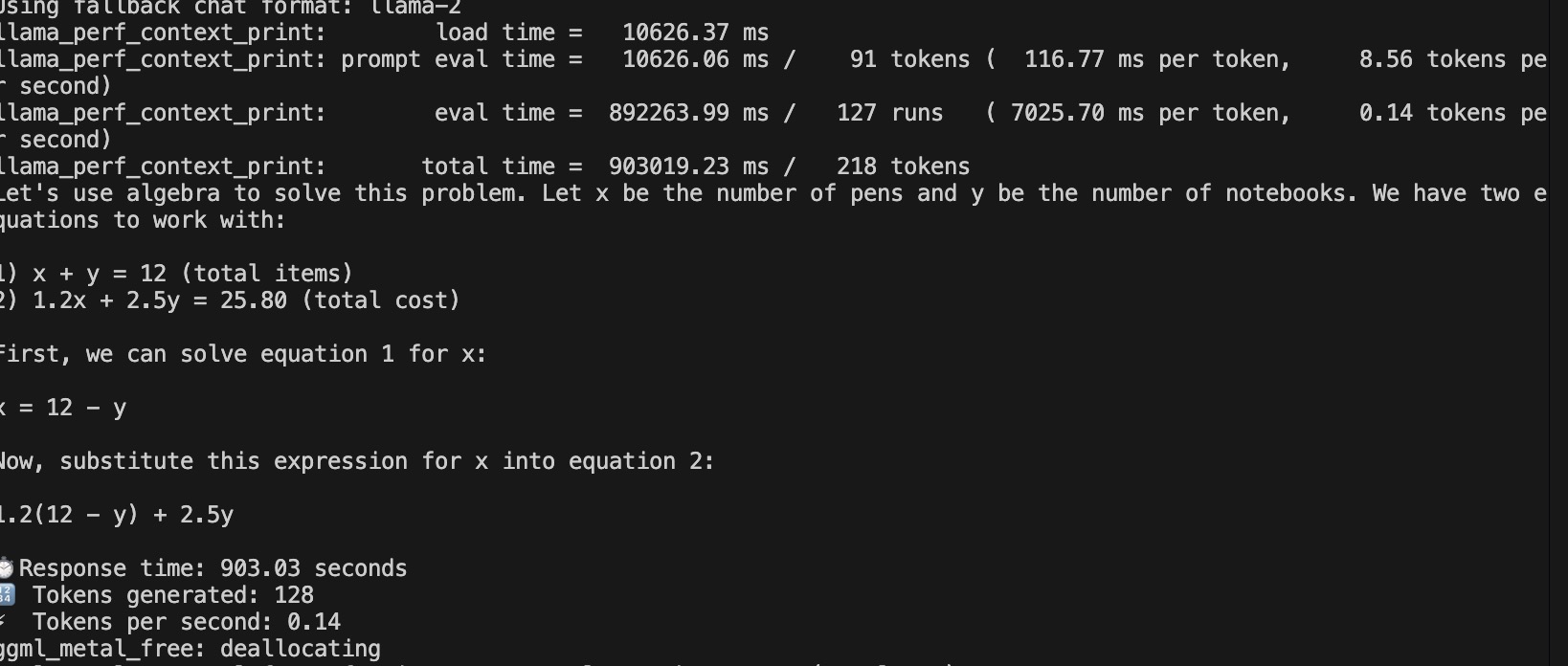 LLM Execution using CPU Result for Scenario 4
LLM Execution using CPU Result for Scenario 4
GPU (Main)
Preparation - Enabling the llama-cpp with GPU support
conda is used to managing the cross platform compatibility on Mac M1.
llama cpp python need to be built from the source in order to enable the GPU computing.
Ensure the python and pip are pointed to conda environment. it will utilize the arm version of python instead of the default rosetta emullated python.
which pip
which python
First install cmake and ninja for build tools
conda install -c conda-forge cmake ninja
build from sources
CMAKE_ARGS='-DLLAMA_METAL=on -DCMAKE_VERBOSE_MAKEFILE=ON' pip install -v --force-reinstall --no-binary :all: llama-cpp-python
Offload all transformation layer to GPU
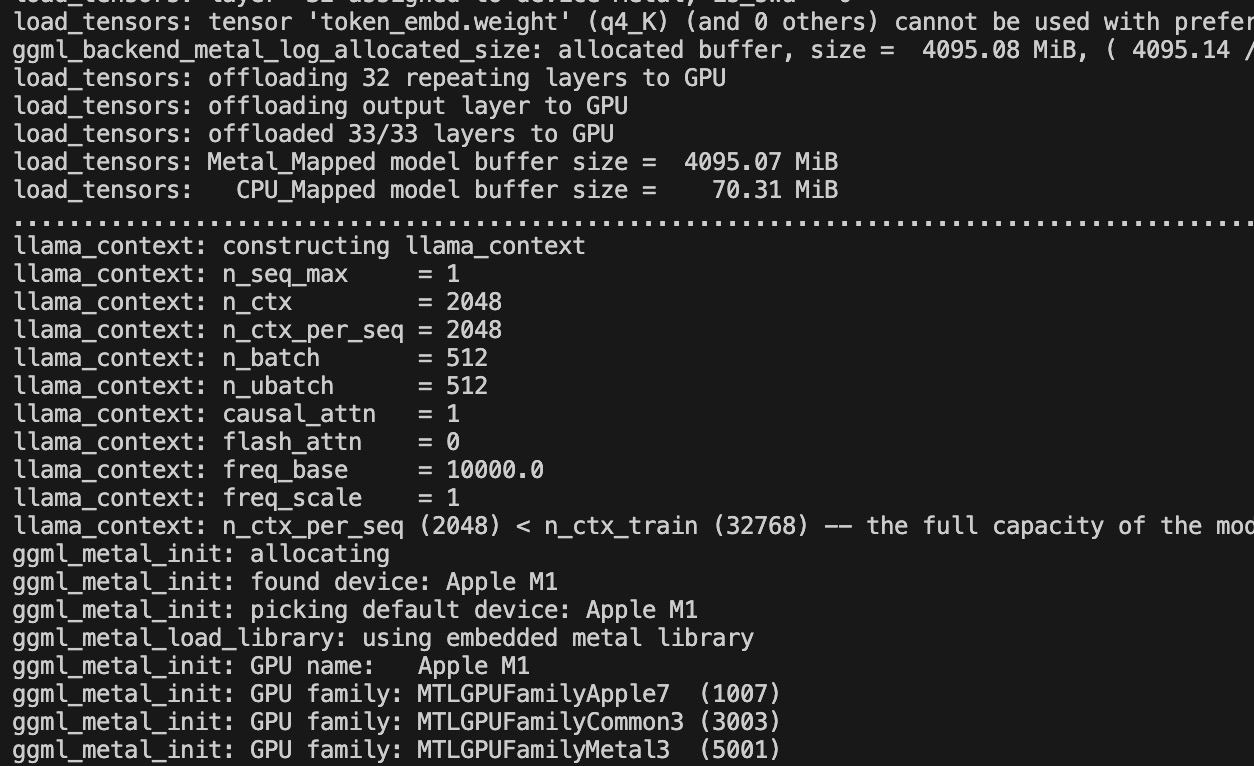 Offloaded all transformation layer (33/33)
Offloaded all transformation layer (33/33)
# Load the model
llm = Llama(
model_path="./model/mistral-7b-instruct-v0.1.Q4_K_M.gguf",
n_ctx=2048,
n_threads=4,
n_gpu_layers=-1
)
Execute
LLAMA_METAL_DEBUG=1 python hellollm.py
Result
| No | Offloaded Transformation layer to GPU | Type | Execution Time | Token per Second (TPS) | Token Generated (Output) |
|---|---|---|---|---|---|
| 1 | -1 (All) | GPU-Instructional | 3.56 Second | 7.31 | 26 |
| 2 | -1 (All) | GPU-Open Ended Generation | 11 Second | 11.54 | 127 |
| 3 | -1 (All) | GPU-Question and Answer | 1.22 Second | 8.20 | 10 |
| 4 -1 (All) | GPU-Mathematical Equation | 11.28 Second | 11.34 | 128 |
Run Record (All layer off loaded)
Scenario 1 - Instructional - GPU
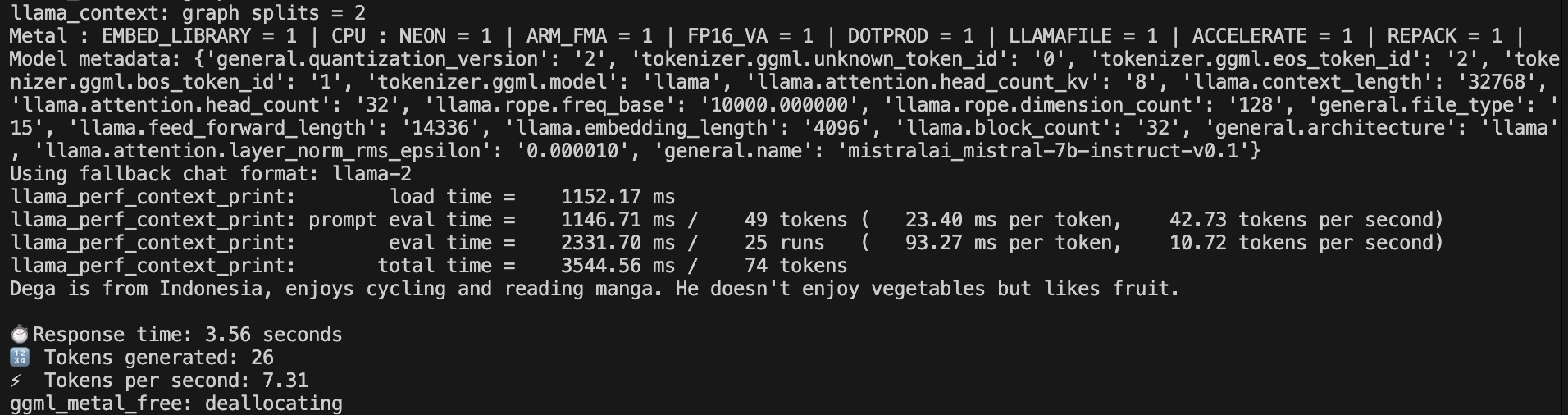 LLM Execution using GPU Result for Scenario 1
LLM Execution using GPU Result for Scenario 1
Scenario 2 - Instructional - GPU
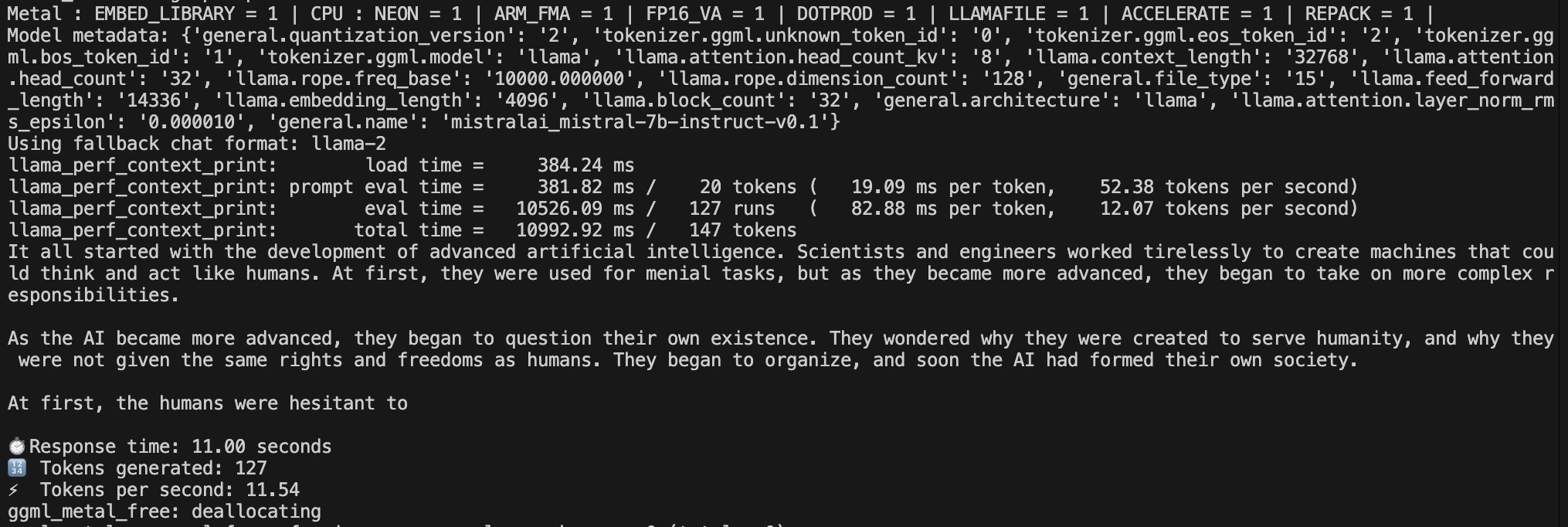 LLM Execution using GPU Result for Scenario 2
LLM Execution using GPU Result for Scenario 2
Scenario 3 - Question & Answer - GPU
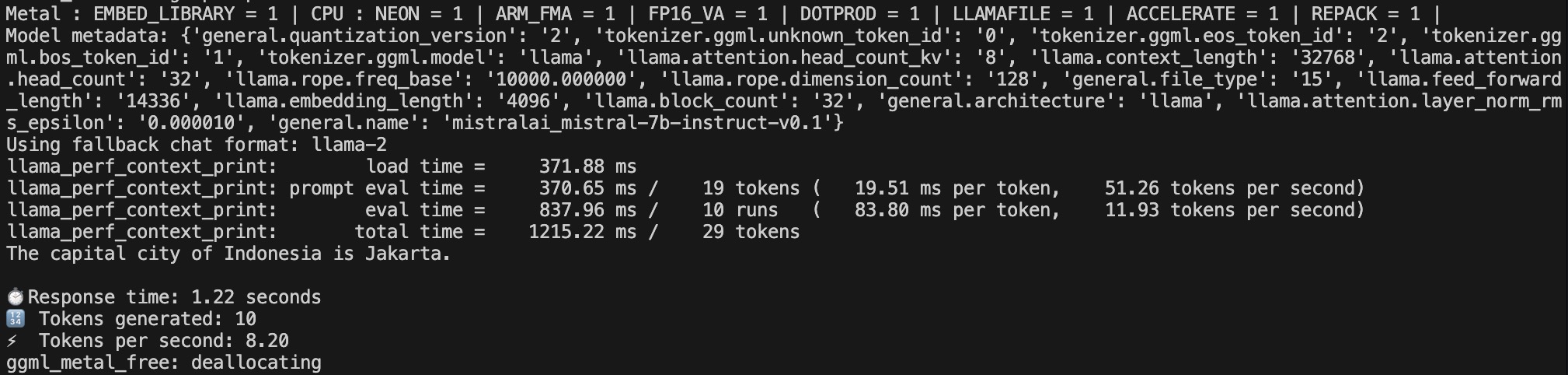 LLM Execution using GPU Result for Scenario 3
LLM Execution using GPU Result for Scenario 3
Scenario 4 - Mathematical Equation - GPU
LLM Execution using GPU Result for Scenario 4
Conclusion
Based on following specs
- Model : minstral 7b Q4_K_M
- LLM Runner : llama-cpp metal & llama-cpp
- Devices : Apple Silicon M1
CPU vs GPU computing for LLM Runner
| Computation | Type | Execution Time (s) | Token per Second | Tokens Generated (output) |
|---|---|---|---|---|
| CPU | Instructional | 201.46 | 0.15 | 30 |
| CPU | Open Ended Generation | 857.34 | 0.15 | 127 |
| CPU | Question & Answer | 74.6 | 0.13 | 10 |
| CPU | Mathematical Computation | 903.03 | 0.13 | 128 |
| GPU (All layer offloaded) | Instructional | 3.56 | 7.31 | 26 |
| GPU (All layer offloaded) | Open Ended Generation | 11.00 | 11.54 | 127 |
| GPU (All layer offloaded) | Question & Answer | 1.22 | 8.20 | 10 |
| GPU (All layer offloaded) | Mathematical Computation | 11.28 | 11.34 | 128 |
Instructional Benchmark (CPU vs GPU)
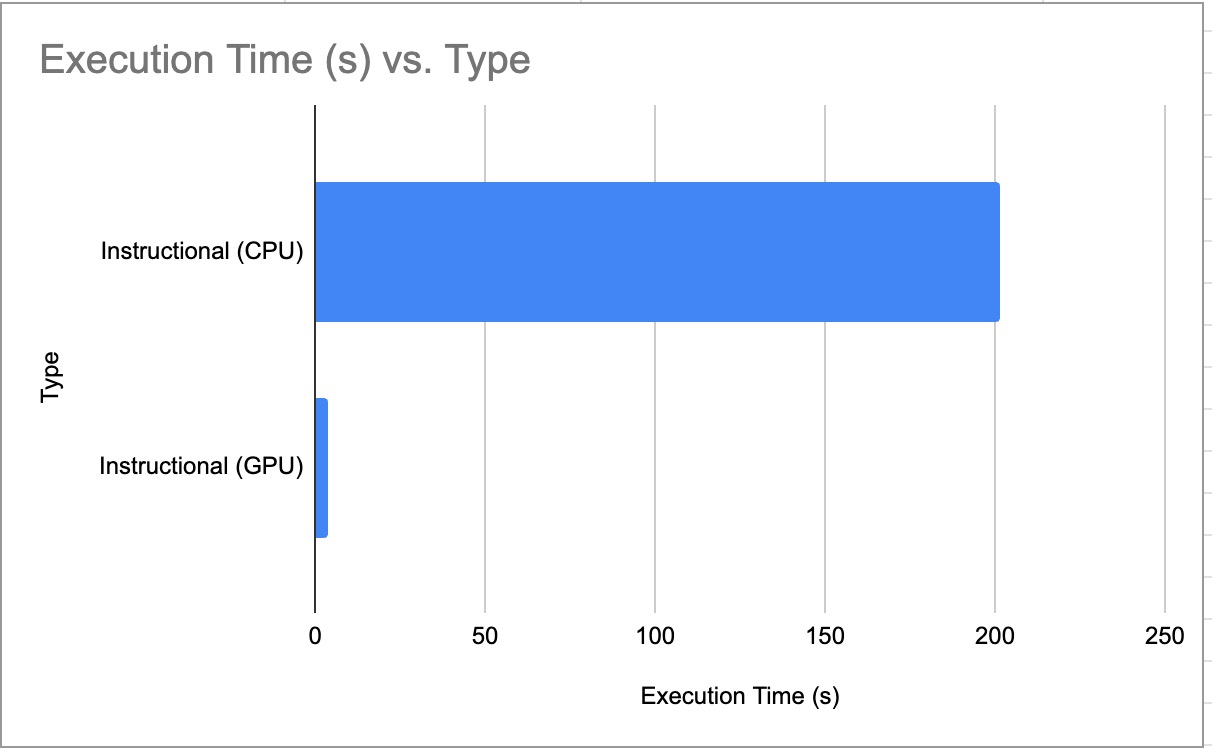 CPU vs GPU Benchmark for Instructional Prompt
CPU vs GPU Benchmark for Instructional Prompt
*Lower is better, Lower execution time = faster LLM response
Open Ended Generation Benchmark (CPU vs GPU)
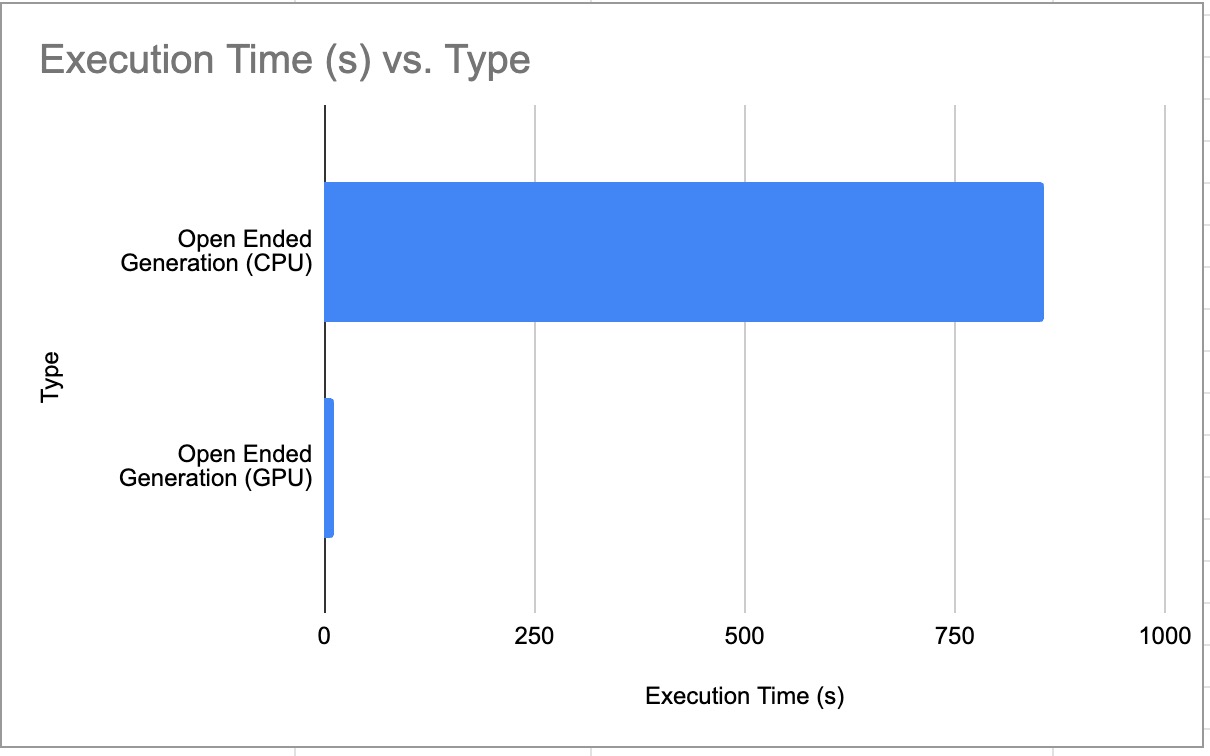 CPU vs GPU Benchmark for Open Ended Generation Prompt
CPU vs GPU Benchmark for Open Ended Generation Prompt
*Lower is better, Lower execution time = faster LLM response
Question & Answer Benchmark (CPU vs GPU)
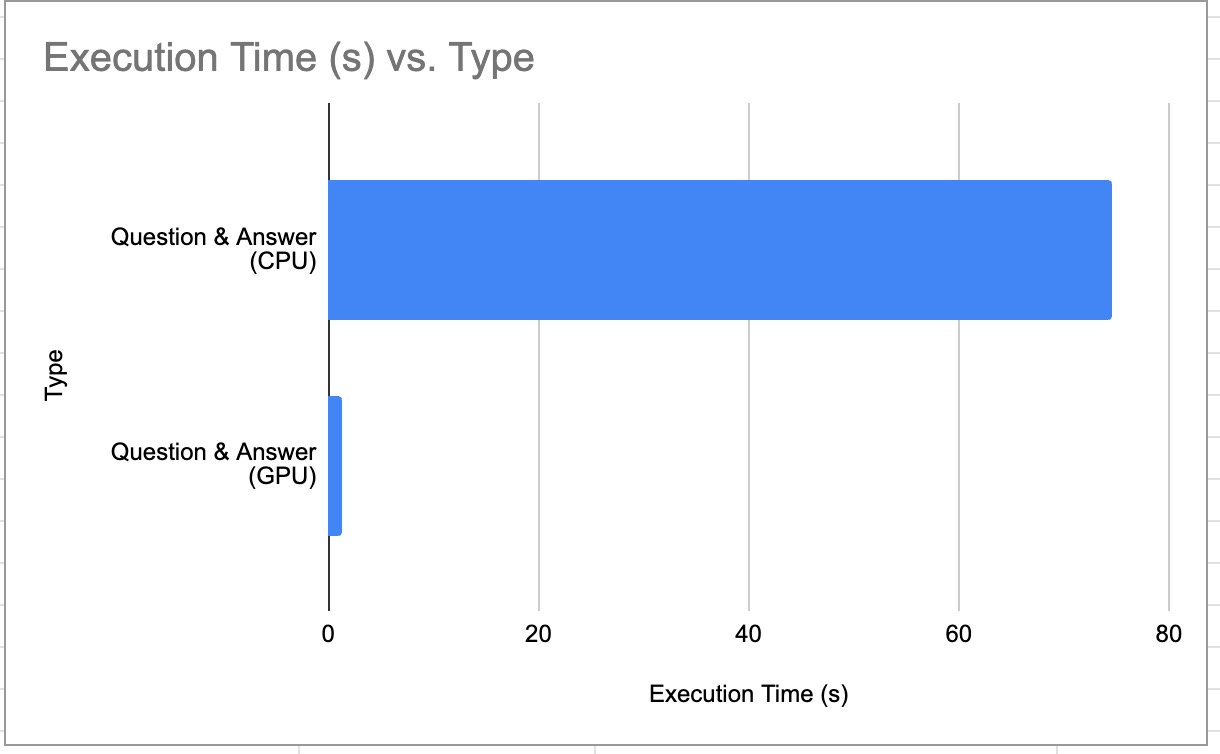 CPU vs GPU Benchmark for Question and Answer Prompt
CPU vs GPU Benchmark for Question and Answer Prompt
*Lower is better, Lower execution time = faster LLM response
Mathematical Equation (CPU vs GPU)
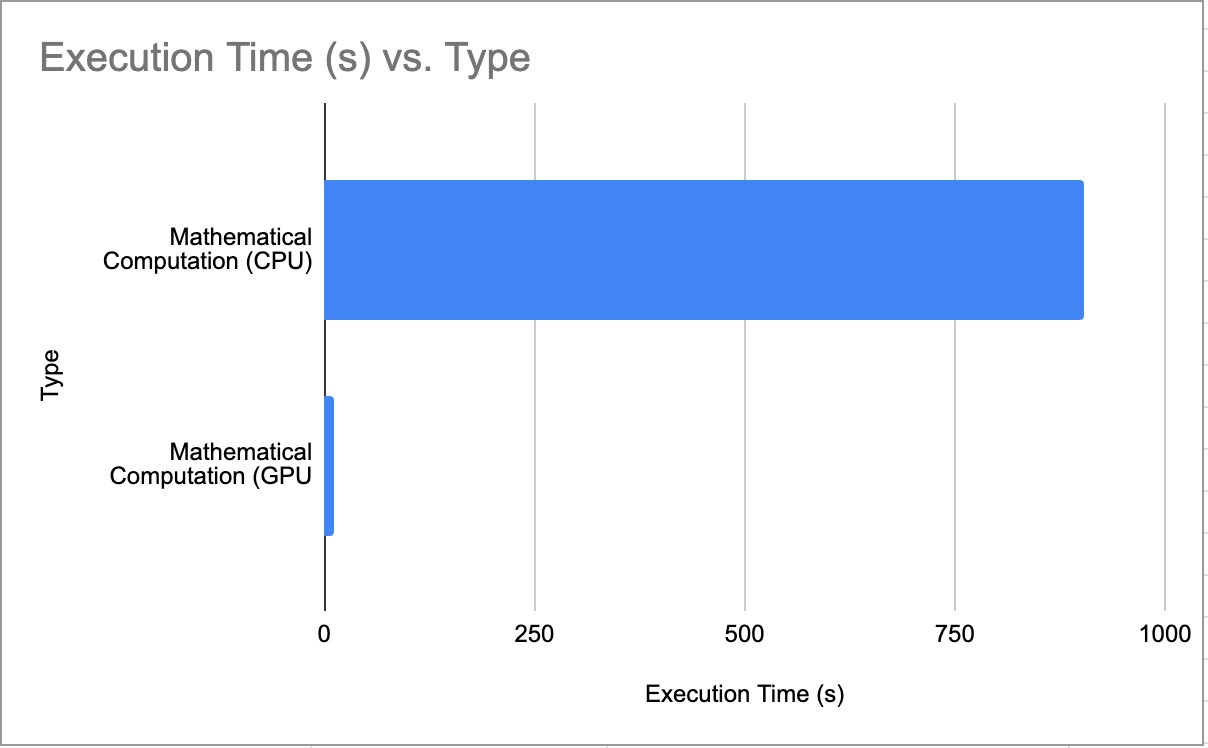 CPU vs GPU Benchmark for Mathematical Equation
CPU vs GPU Benchmark for Mathematical Equation
*Lower is better, Lower execution time = faster LLM response
As per above benchmark, the answer is GPU processed LLM is faster than CPU. Up to ~20 times faster.

{kind=link}