Creating the python project
Generally there two approach to create python environment for one specific project
Its recommended to use miniconda to manage several python environment
python version 3.10.x & Apple Silicon M1 Processor will be used on this article.
Creating project using miniconda
following syntax will create python environment with specific python version.
conda create --name hello-world-minstral python=3.10
Creating project using python venv
by default python can also create virtual environment using following syntax
python -m venv hello-world-minstral
however, the environment will be created based on the python version used.
python --version
python 3.10 need to be exposed to the path first, before creating the virtual environment.
thats why its generally recommended to use miniconda to create python project as its easier to manage different python version without the need of managing multiple $PATH (if in windows)
notes: conda also handled cross platform compatibilities. for example, on mac silicon case, conda will handle the cross platform dependencies and the package has been optimized for M1/M2/M3/M4
Installing dependencies for Minstral 7b
switch to the newly created conda environment “hello-world-minstral”.
view available conda environment
conda env list
activate the hello-world-minstral environment
conda activate hello-world-minstral
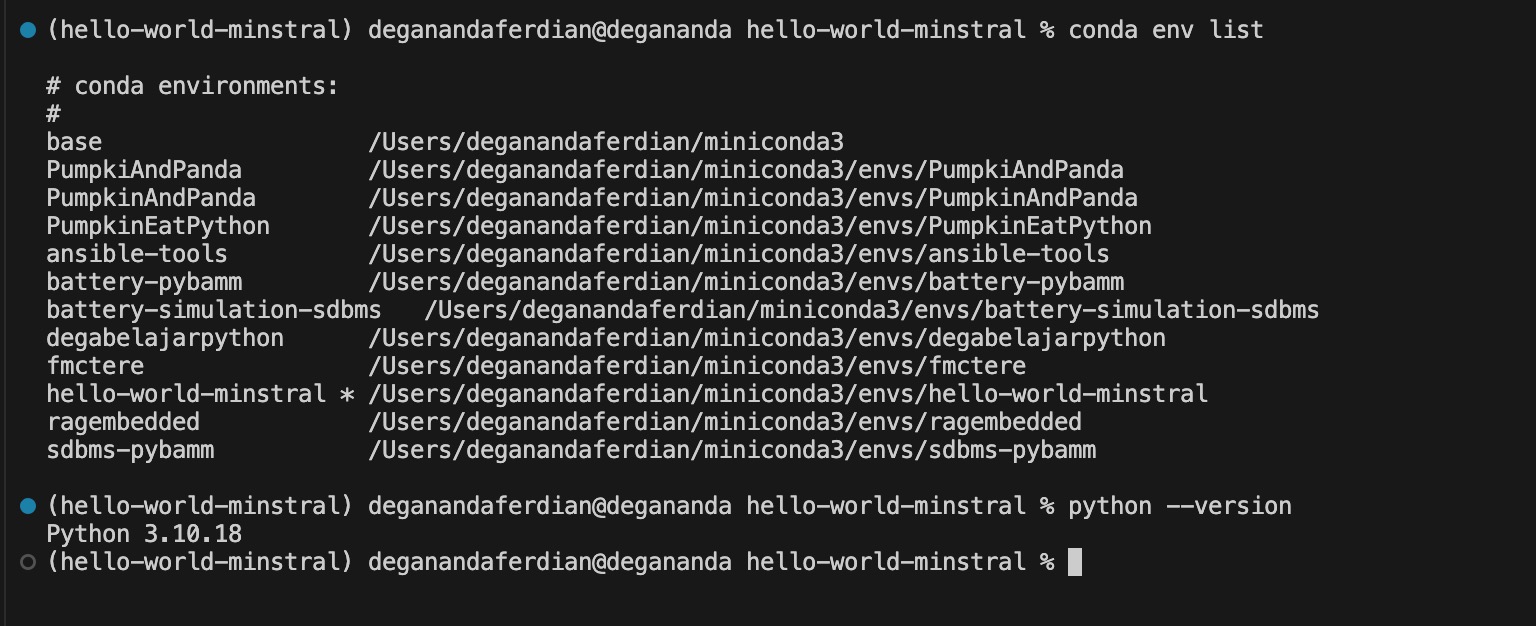 Check python version & activated conda environment
Check python version & activated conda environment
ensure the python environment is 3.10.18 (after activating conda environment)
python --version
Install Inference engine (llama-cpp)
CPU Only
zsh
init the conda
conda init zsh
install llama-cpp-python
pip install "llama-cpp-python"
bash
pip install llama-cpp-python
Wait until the installation is completed.
 Installing LLM Runner : llama-cpp with support for apple silicon M series
Installing LLM Runner : llama-cpp with support for apple silicon M series
Llama-cpp with GPU Support
build directly from the sources
CMAKE_ARGS='-DLLAMA_METAL=on' pip install --force-reinstall --no-binary :all: llama-cpp-python
What is Inference Engine?
a C++ inference engine needed to run quantized LLM locally and metal version of llama-cpp for GPU support on silicon M1.
Inference engine = LLM Runner, and Llama-Cpp in inference engine based on C++ which can support CPU and GPU.
Inference engine responsible for following things :
- load the trained model (minstral, LLaMA, etc)
- Process the prompt input
- Generate output (after input send to the loaded model and capture the responses)
Download the Model (GGUF Format)
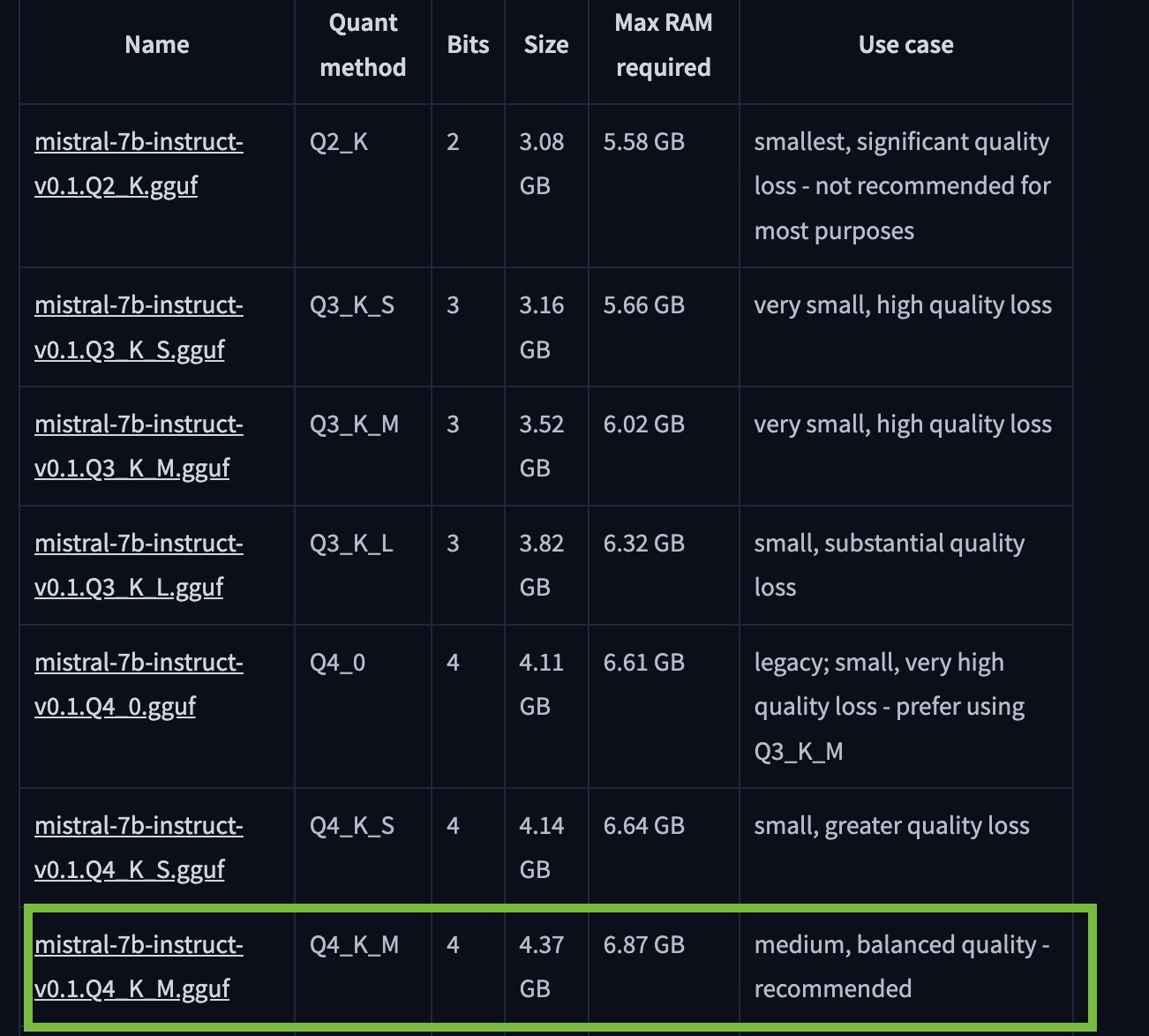 Q4_K_M is lightweight but yet still usable
Q4_K_M is lightweight but yet still usable
Apple M1 with 8 gb of ram will be used to ran the LLM. One of the minstral model that fit for this case is : Minstral 7B Q4_K_M
Minstral 7B Q4_K_M require +- 6 gb of RAM.
Download following Files
https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF
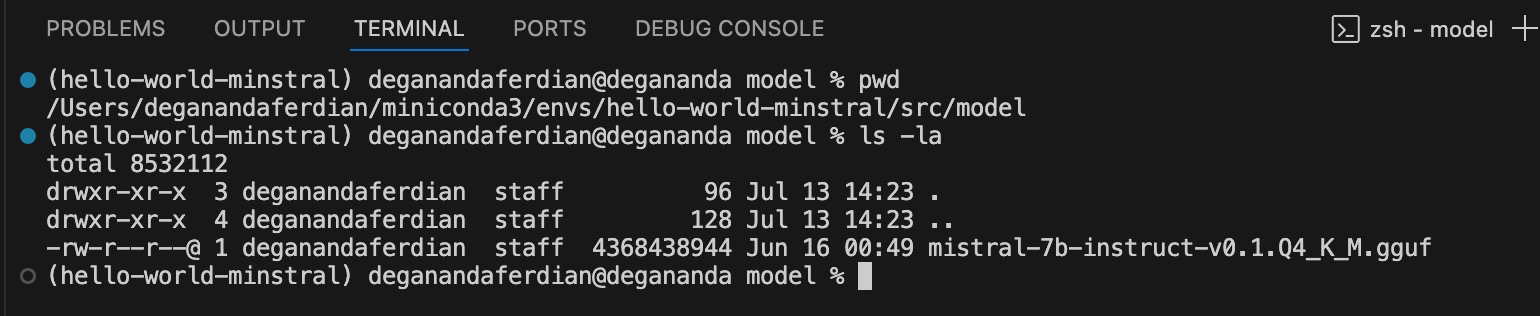
Create new folder called “model” on the miniconda project and store the Minstral 7b Q4_K_M GGUF
cp Mistral-7B-Instruct-v0.1-GGUF /src/model
Load the model & run it
Ensure llama_cpp_python is installed. On this artcle version 0.3.12 is used with python 3.10.18
create a new python file called as “hellollm.py”
from llama_cpp import Llama
# Load the model
llm = Llama(
model_path="mistral-7b-instruct-v0.1.Q4_K_M.gguf",
n_ctx=2048,
n_threads=4,
)
# Prompt the model
output = llm(
prompt="### Instruction:\nSay hello to the world.\n\n### Response:",
max_tokens=128,
stop=["###"]
)
# Print result
print(output["choices"][0]["text"].strip())
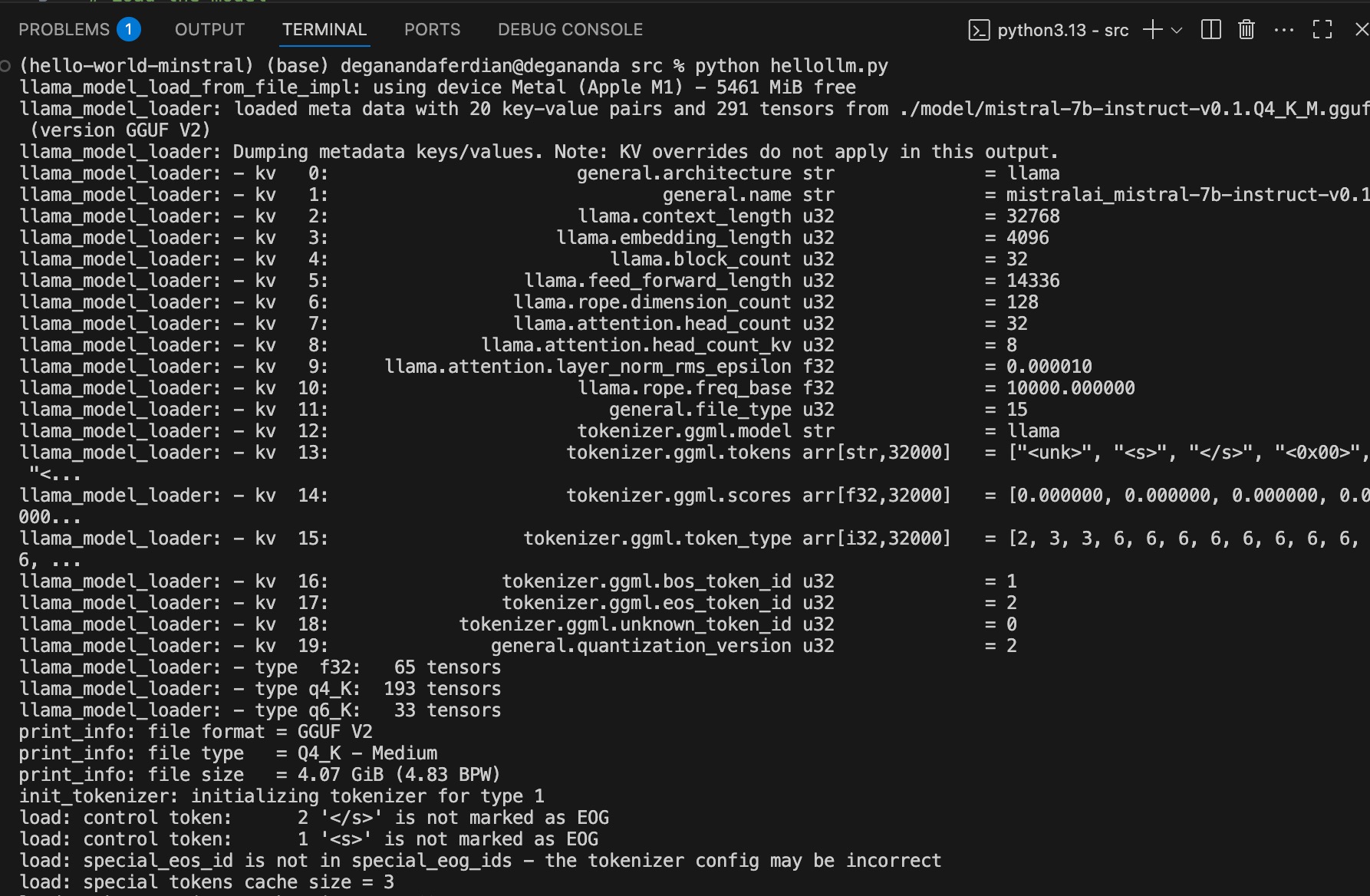 run minstral Q4_K_M using llama-cpp-python
run minstral Q4_K_M using llama-cpp-python
run it
python hellollm.py
it should expect following responses.
Hello, world! It's great to be here and ready to assist you with any information or tasks you might have. How can I help you today?
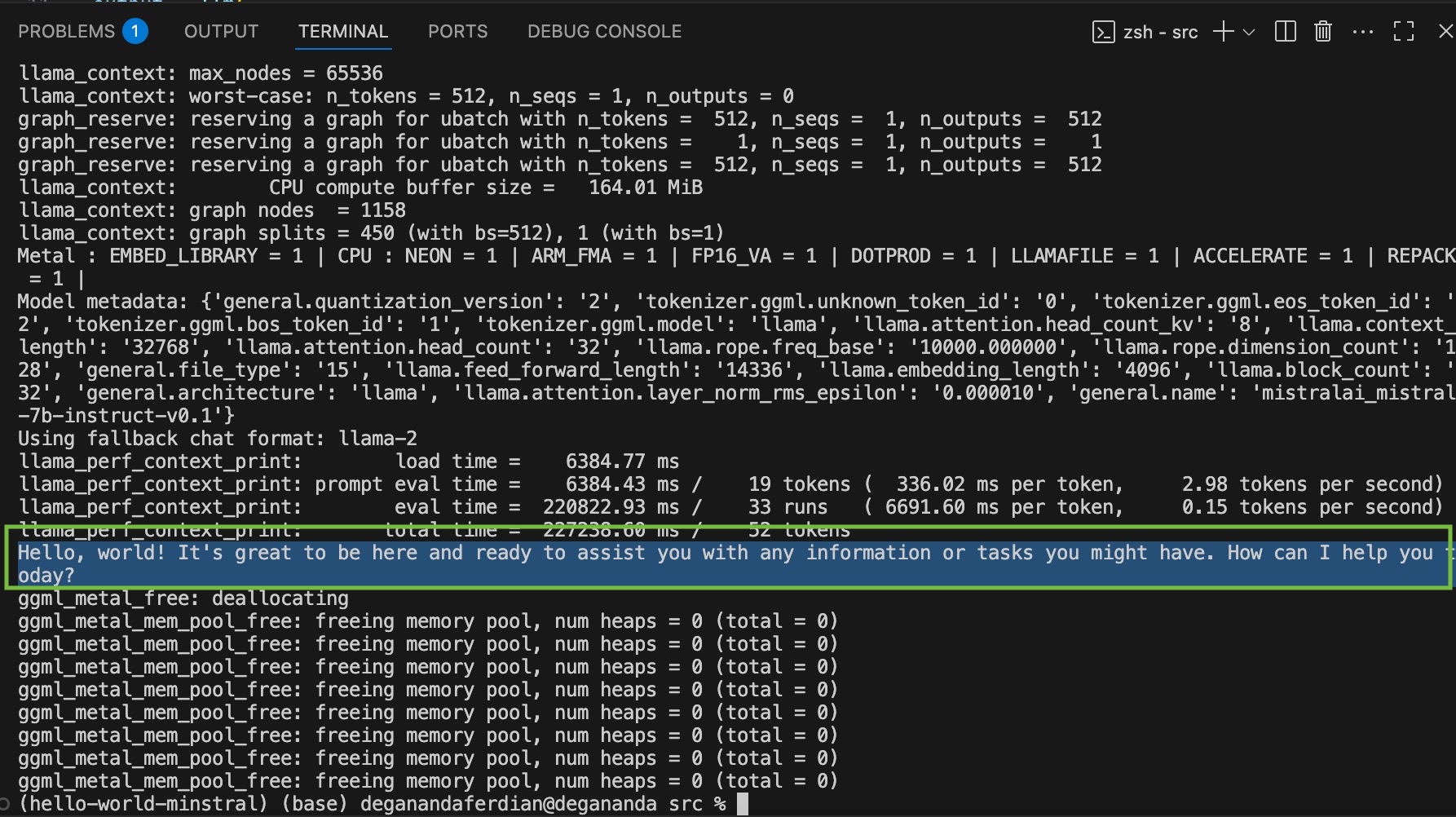 Minstral 7b responses to the hello world instruction
Minstral 7b responses to the hello world instruction
Calculating Response time
import time
to compute the execution time from the input prompt collection by LLM runner / inference engine until LLM returning responses, timing code calculation can be added
add start time just before the LLM model took the input
# Prompt the model
prompt = "### Instruction:\nSay hello to the world.\n\n### Response:"
start_time = time.time()
output = llm(
prompt=prompt,
max_tokens=128,
stop=["###"]
)
and add endtime after the output generated
output = llm(
prompt=prompt,
max_tokens=128,
stop=["###"]
)
end_time = time.time()
print the responses time
print(f"\n⏱️ Response time: {end_time - start_time:.2f} seconds")
