Article Pre-Requisite
Consuming machine learning model
before exposing an API to consume the model, a series of test needed to ensure the model can be consumed.
get the joblib file from previous article.
load the joblib model and put in some test input
the input format would be : ['cell', 'module', 'pack', 'energy_density', 'power_density', 'c_rate', 'cycle_life', 'efficiency', 'self_discharge_rate', 'thickness', 'calendering_pressure', 'min_temp', 'max_temp']
import joblib
from sklearn.ensemble import RandomForestClassifier
model: RandomForestClassifier = joblib.load('battery_model.joblib')
predict.
import joblib
from fastapi import FastAPI
from sklearn.ensemble import RandomForestClassifier
model: RandomForestClassifier = joblib.load('battery_model.joblib')
features : list[float] = [15.5,346.55,2639.2,257.96,382.48,1.91,2530,97.38,1.03,76.43,123.02,-25.0,65.0]
prediction = model.predict([features])
print(prediction)
Expose to API
there are two ways to exposing the model to an API (so that FE/any system can call the model and supplying the input features).
MLFlow
Installation
Install pyarrow
pip install pyarrow
Install mlflow (dependent on pyarrow)
pip install mlflow
install pyenv
brew install pyenv
Run ML Flow UI
ensure mlflow is properly installed
mlflow -version
execute following command to run mlflow server
mlflow ui
open on the browser
http://127.0.0.1:5000/
 MLFlow by default is exposed and listening to port 5000, open it on browser
MLFlow by default is exposed and listening to port 5000, open it on browser
Integrate local code to MlFlow
integrate local train.py with ML Flow
things that will be integrated: log model, experiment tracking, and performance monitoring
update train.py
#Pandas
import pandas as pd
from pandas import DataFrame
#SkLearn
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
#Model Generator
import joblib
# mlflow
import mlflow
import mlflow.sklearn
from mlflow.models.signature import infer_signature
# Load csv dataset to data frame
batteryGradingDataSet = './battery_classification_dataset_100.csv'
batterGradingDataFrame : DataFrame = pd.read_csv(batteryGradingDataSet)
# Cleansing & Transform
batterGradingDataFrame[['min_temp', 'max_temp']] = batterGradingDataFrame['operating_temperature'].str.extract(r'(-?\d+)\s*to\s*(-?\d+)').astype(float)
batterGradingDataFrame.drop(columns='operating_temperature', inplace=True)
# List down feature column
labelIndex = "performance_grade"
featureColumn : list[str] = []
for col in batterGradingDataFrame.columns:
if col != "id" and col != labelIndex:
featureColumn.append(col)
x = batterGradingDataFrame[featureColumn]
x.astype("float64")
y = batterGradingDataFrame[labelIndex]
print(batterGradingDataFrame.head())
print(featureColumn)
# Apply Standard Scaler
scaler = StandardScaler()
x_scaled = scaler.fit_transform(x)
# Test Splitting & Random Seed
test_size = 0.2
random_seed = 42
# Split the data
x_train, x_test, y_train, y_test = train_test_split(
x_scaled, # Your input features (after scaling)
y, # Your target/label values
test_size=test_size, # 20% test, 80% train
random_state=random_seed, # Ensures reproducibility
stratify=y # Keep class distribution balanced in both sets
)
#Train model with classification model (random forest)
# Integrate training process with ML flow.
with mlflow.start_run() as run:
run_id = run.info.run_id
mlflow.set_experiment("Battery Grading")
model = RandomForestClassifier(random_state=random_seed)
model.fit(x_train, y_train)
#Evaluate model (get the accuracy)
y_pred = model.predict(x_test)
accuracy = accuracy_score(y_test, y_pred)
print(classification_report(y_test, y_pred))
mlflow.log_param("random_seed", random_seed)
mlflow.log_metric("accuracy", accuracy)
#Export the model for further use without training
joblib.dump(model, 'battery_performance_model.joblib')
signature = infer_signature(x)
# Log the model along with the signature and input example
mlflow.sklearn.log_model(
sk_model=model,
artifact_path=f"battery_performance_model_{run_id}",
signature=signature,
input_example=x
)
Run the train.py model
execute following command
python3 train.py
check ML Flow UI, the experiment logs and history will be shown.
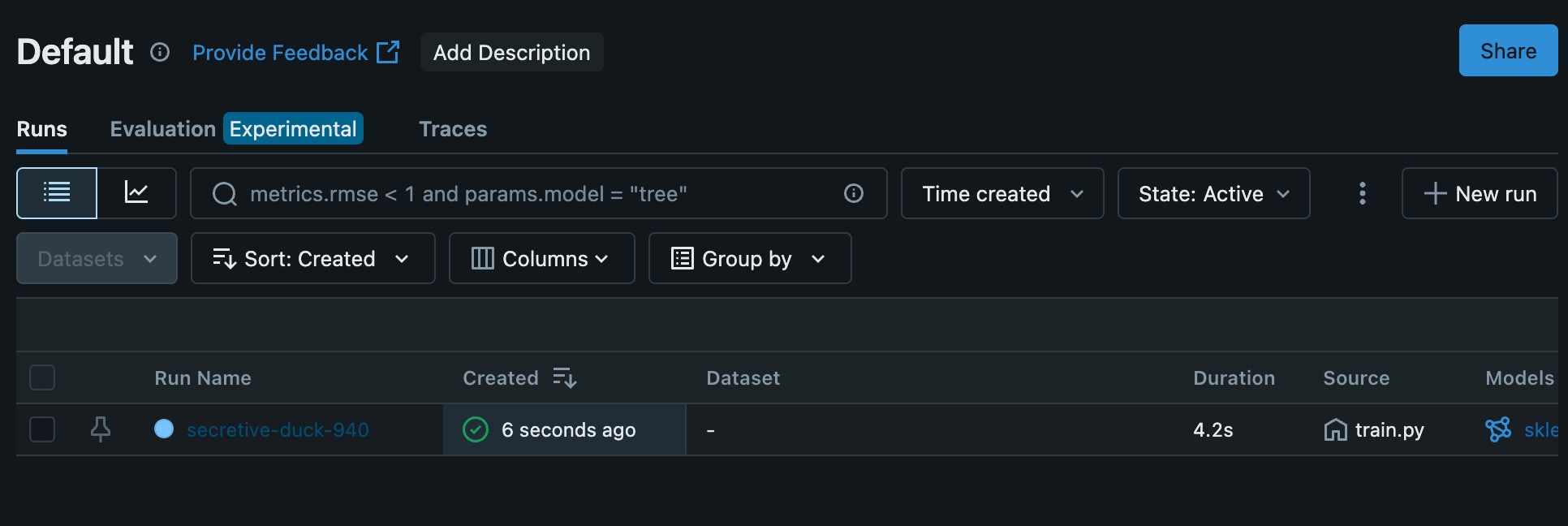
Executing artifact
since the artifact is logged (log_model), every run of the experinment it will create an artifact. This artifact can be deployed over HTTP protocol and can be directly used for testing (HTTP Invocation)
go to artifact on the specific run that would like to be deployed
copy the run id and execute following command
mlflow models serve -m runs:/<runId>/battery_performance_model_<runId> -p 1234 --no-conda
this will expose the artifact to port 1234
Result
invoke the API
curl --location 'http://localhost:1234/invocations' \
--header 'Content-Type: application/json' \
--data '{
"dataframe_split": {
"columns": [
"cell",
"module",
"pack",
"energy_density",
"power_density",
"c_rate",
"cycle_life",
"efficiency",
"self_discharge_rate",
"thickness",
"calendering_pressure",
"min_temp",
"max_temp"
],
"data": [
[
15.5,
346.55,
2639.2,
257.96,
382.48,
1.91,
2530,
97.38,
1.03,
76.43,
123.02,
-25,
65
],
[
6.17,
163.32,
1369.28,
130.04,
259.38,
0.81,
1013,
85.25,
3.36,
99.37,
77.24,
5,
40
]
]
}
}'
once the curl is executed, it will return following result:
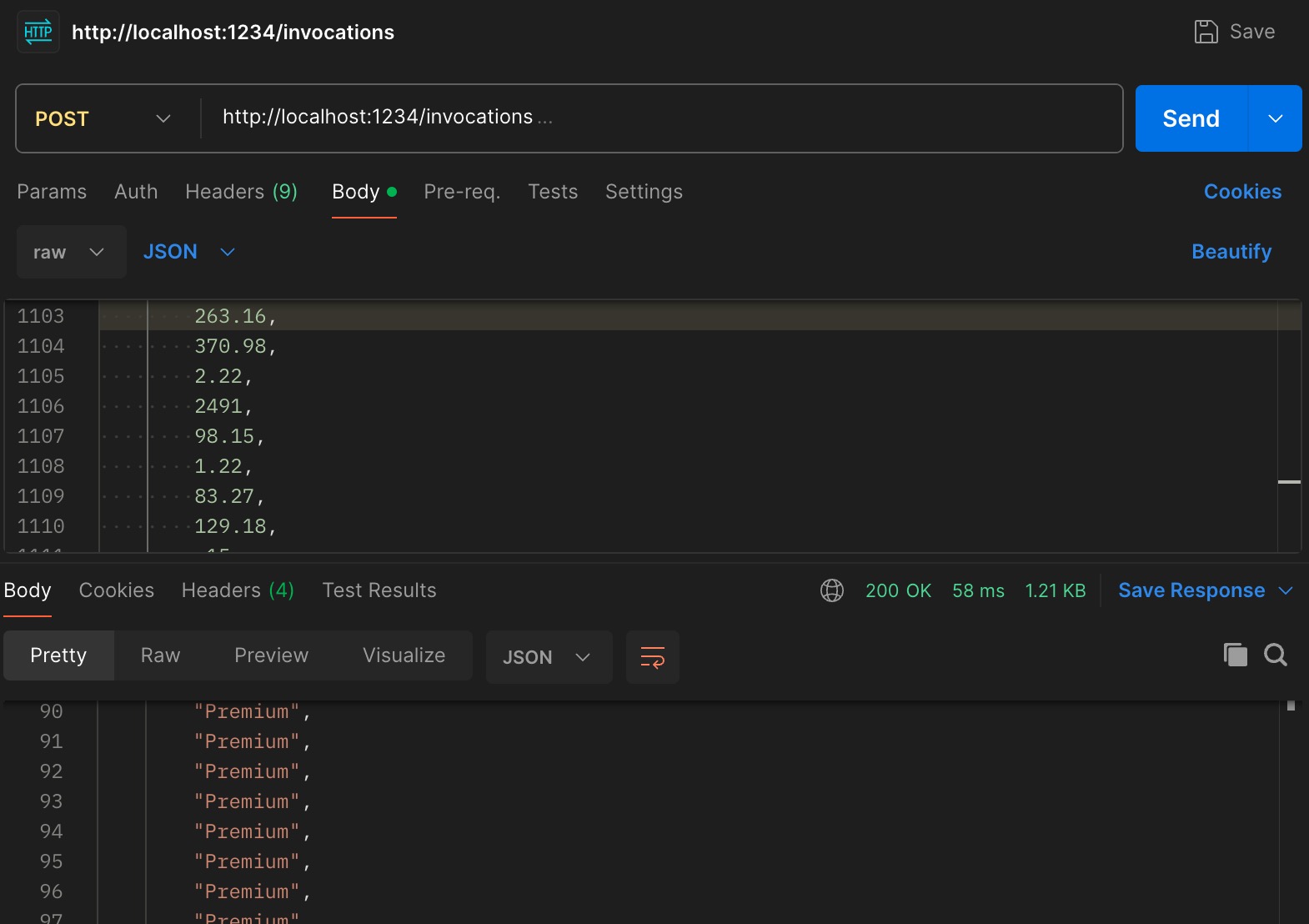 exposed joblib model on Mlflow : Invocation
exposed joblib model on Mlflow : Invocation
if everything is successful then the API will return prediction for each submitted feature (on the JSON Body).
its recommended to use mlflow server for testing purposes, to actually deploy on production server its best to use FastAPI to have full control over the API Server (eg: security, validation, integration with other BE services, etc)
Fast API
Create API Services that Consume JobLib Model
Install fastapi uvicorn (used to server on the fastapi basically the equivalent of nodemon on nodejs (if you’re familiar with nodejs))
pip install fastapi uvicorn
create an POST endpoint (“/batteryperformance”) that receive following faeture/json body parameter
['cell', 'module', 'pack', 'energy_density', 'power_density', 'c_rate', 'cycle_life', 'efficiency', 'self_discharge_rate', 'thickness', 'calendering_pressure', 'min_temp', 'max_temp']
app.py
import joblib
from fastapi import FastAPI
from sklearn.ensemble import RandomForestClassifier
from pydantic import BaseModel
import numpy as np
model: RandomForestClassifier = joblib.load('battery_model.joblib')
app = FastAPI()
class Features(BaseModel):
cell : float
module: float
pack : float
energy_density :float
power_density: float
c_rate : float
cycle_life : float
efficiency : float
self_discharge_rate : float
thickness : float
calendering_pressure : float
min_temp :float
max_temp : float
#features : list[float] = [15.5,346.55,2639.2,257.96,382.48,1.91,2530,97.38,1.03,76.43,123.02,-25.0,65.0]
#prediction = model.predict([features])
#print(prediction)
@app.post("/batteryperfromance/")
def predict(features: Features):
feature_list = [
features.cell,
features.module,
features.pack,
features.energy_density,
features.power_density,
features.c_rate,
features.cycle_life,
features.efficiency,
features.self_discharge_rate,
features.thickness,
features.calendering_pressure,
features.min_temp,
features.max_temp,
]
input_data = np.array(feature_list).reshape(1, -1)
prediction = model.predict(input_data)
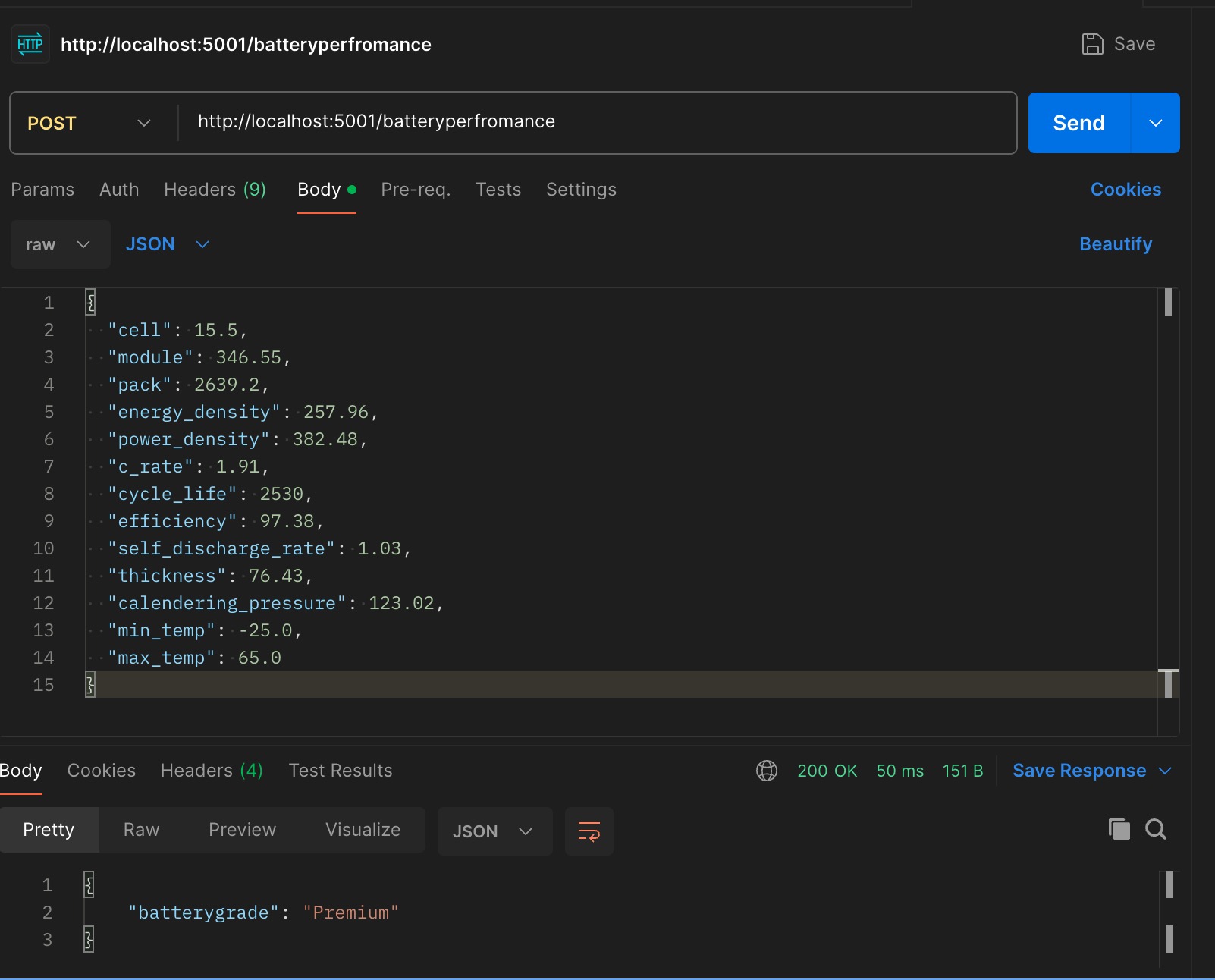
return {"batterygrade": prediction[0]}
run the builder/server (uvicorn)
uvicorn app:app --reload --host 0.0.0.0 --port 5001
to run on the background
nohup uvicorn app:app --reload --host 0.0.0.0 --port 5001
test invocation
curl --location 'http://localhost:5001/batteryperfromance' \
--header 'Content-Type: application/json' \
--data '{
"cell": 15.5,
"module": 346.55,
"pack": 2639.2,
"energy_density": 257.96,
"power_density": 382.48,
"c_rate": 1.91,
"cycle_life": 2530,
"efficiency": 97.38,
"self_discharge_rate": 1.03,
"thickness": 76.43,
"calendering_pressure": 123.02,
"min_temp": -25.0,
"max_temp": 65.0
}'
API Invocation Result
test via postman