Article Pre-Requisite
1.use case description for battery performance
Generate Data Sets
Feature list
a Mockdataset. Dataset will be generated using AI. Its not retrieved actual data from the industries.
a battery perfromance grading will be determined on following features
- 1.Cell level: Capacity/energy at single cell level (Wh or mAh)
- 2.Module Level: Performance at module level (Wh)
- 3.Pack level: Total energy at pack level (Wh or kWh)
- 4.Energy Density: Wh/kg
- 5.Power Density: W/kg
- 6.C Rate: Charge/discharge rate (e.g., 1C = full charge in 1 hour)
- 7.Cycle Life: Number of full charge-discharge cycles
- 8.Charge / Discharge Efficiency: % efficiency
- 9.Self Discharge Rate: % lost per month
- 10.Operating Temperature: Min–max °C
- 11.Thickness: Thickness of electrode (micrometers)
- 12.Calendering Pressure: Pressure applied during electrode manufacturing (MPa)
Data Sets
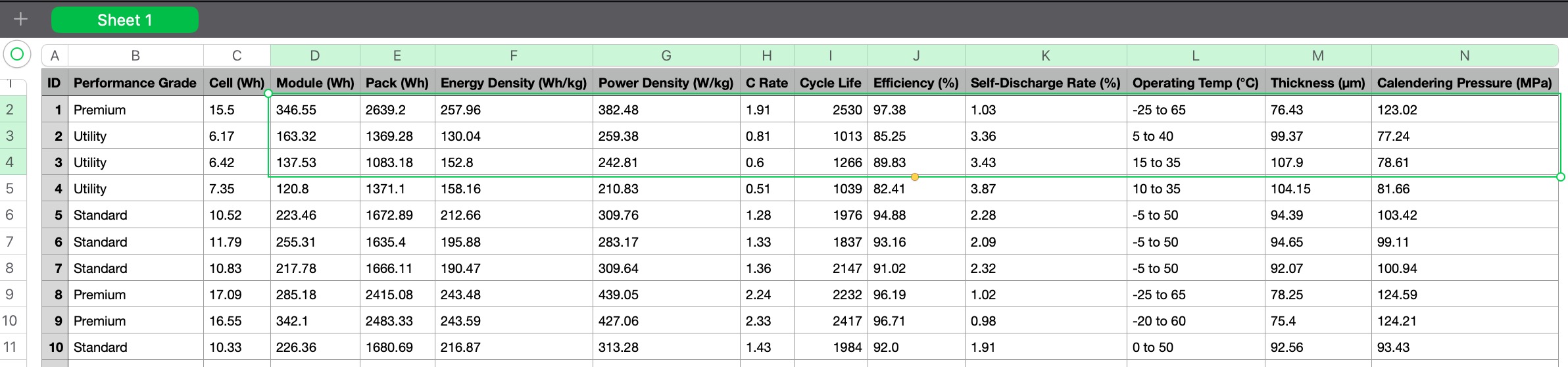 a Mock Data set for Battery specs and pre defined grading
a Mock Data set for Battery specs and pre defined grading
in real world scenario, data sets will be provided by the industry expert. bad data set will result in bad ML model. Resulting in false positive or false negative. Garbage In -> Garbage Out
download here : battery_classification_dataset_100.csv
Data Cleansing
Skipped on this article due to the pre-defined data set (already clean)
Exploratory Data Analysis
Skipped on this article due to the pre-defined data set (already clean)
Training the model
Create a data frame
before training the model, all the data set need to be put on the data frame. Pandas library will be used.
pip install pandas
confirm whether the package is successfully installed.
pip list | grep pandas
previouly generated mock data set for battery grading with 12 features need to be loaded on the pandas data frame.
import pandas as pd
from pandas import DataFrame
# Load csv dataset to data frame
batteryGradingDataSet = './battery_classification_dataset_100.csv'
batterGradingDataFrame : DataFrame = pd.read_csv(batteryGradingDataSet)
Determining feature and label column
to be able to make prediction, list of feature need to be put on X Axis and list of predicted label (on this case is performance_grade) need to be put on Y Axis.
# List down feature column
labelIndex = "performance_grade";
featureColumn : list[str] = []
for col in batterGradingDataFrame.columns:
if col != "id" or col != labelIndex:
featureColumn.append(col)
x = batterGradingDataFrame[featureColumn]
y = batterGradingDataFrame[labelIndex]
Cleanse data
there is one column that have “string” value which can’t be converted to float by the standard scaler(later part).
-25 to 50 is the sample value for operating temperature.
the data need to be transformed into two column (“min_temp” and “max_temp”) and finally drop the original “operating_temperature”
batterGradingDataFrame[['min_temp', 'max_temp']] = batterGradingDataFrame['operating_temperature'].str.extract(r'(-?\d+)\s*to\s*(-?\d+)').astype(float)
batterGradingDataFrame.drop(columns='operating_temperature', inplace=True)
Apply Standard Scaler
import pandas as pd
from pandas import DataFrame
from sklearn.preprocessing import StandardScaler
# Load csv dataset to data frame
batteryGradingDataSet = './battery_classification_dataset_100.csv'
batterGradingDataFrame : DataFrame = pd.read_csv(batteryGradingDataSet)
# List down feature column
labelIndex = "performance_grade";
featureColumn : list[str] = []
for col in batterGradingDataFrame.columns:
if col != "id" or col != labelIndex:
featureColumn.append(col)
x = batterGradingDataFrame[featureColumn]
y = batterGradingDataFrame[labelIndex]
# Apply Standard Scaler
scaler = StandardScaler()
x_scaled = scaler.fit_transform(x)
ML Algorithms that going to be used on this case is random forest classifier. Those model will be perform better if the feature (column X) are on same scale.
same scale meaning : Mean of 0 and standard deviation of 1
Set test size
Not all of the rows (out of 100) will be used for training. Some percentage of the data will be use to validate.
# Test Splitting
test_size = 0.2
on this case 20% (20 out of 100 will be used to test/validate)
Set randoom seed
random_seed = 42
random seed is used to split the data using fixed index (on this case is 42). its just a fixed starting point for random number generation.
a funny analog is on magroove recovery. If the seed that planted is different, it might destroy the ecosystem. because it should be magrove only (same type of seed)
Split the data
# Test Splitting & Random Seed
test_size = 0.2
random_seed = 42
# Split the data
x_train, x_test, y_train, y_test = train_test_split(
x_scaled, # Your input features (after scaling)
y, # Your target/label values
test_size=test_size, # 20% test, 80% train
random_state=random_seed, # Ensures reproducibility
stratify=y # Keep class distribution balanced in both sets
)
train_test_split() actually return four value.
(*arrays: Any, test_size: Float | None = None, train_size: Float | None = None, random_state: Int | RandomState | None = None, shuffle: bool = True, stratify: ArrayLike | None = None) -> list
*arrays : sequence of indexables with same length / shape[0]
Allowed inputs are lists, numpy arrays, scipy-sparse matrices or pandas dataframes.
Train the model
from sklearn.ensemble import RandomForestClassifier
#Train model with classification model (random forest)
model = RandomForestClassifier(random_state=random_seed)
model.fit(x_train, y_train)
algorithm that will be used on this article is : random forest classification
Evaluate the model
once the model is created, the remaining 20% of test size data that determinied earlier will be use to test the prediction accuracy
from sklearn.metrics import classification_report, confusion_matrix
y_pred = model.predict(x_test)
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
Model test result
(battery-performance) (base) deganandaferdian@degananda battery-performance % python3 train.py
precision recall f1-score support
Premium 1.00 1.00 1.00 7
Standard 1.00 1.00 1.00 6
Utility 1.00 1.00 1.00 7
accuracy 1.00 20
macro avg 1.00 1.00 1.00 20
weighted avg 1.00 1.00 1.00 20
Omg! its 100% accuracy haha. Of course it would be because the dataset is a mock data that generated by GenAI. its the most ideal dataset.
Export model using job lib
joblib.dump(model, 'battery_model.joblib')
Done.
Full Code
can be found on following github repostiory (public)
https://github.com/deganandapriyambada/battery-performance-ml
or below
#Pandas
import pandas as pd
from pandas import DataFrame
#SkLearn
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
#Model Generator
import joblib
# Visualize
import matplotlib.pyplot as plt
import seaborn as sns
# Load csv dataset to data frame
batteryGradingDataSet = './battery_classification_dataset_100.csv'
batterGradingDataFrame : DataFrame = pd.read_csv(batteryGradingDataSet)
# Cleansing & Transform
batterGradingDataFrame[['min_temp', 'max_temp']] = batterGradingDataFrame['operating_temperature'].str.extract(r'(-?\d+)\s*to\s*(-?\d+)').astype(float)
batterGradingDataFrame.drop(columns='operating_temperature', inplace=True)
# List down feature column
labelIndex = "performance_grade"
featureColumn : list[str] = []
for col in batterGradingDataFrame.columns:
if col != "id" and col != labelIndex:
featureColumn.append(col)
x = batterGradingDataFrame[featureColumn]
y = batterGradingDataFrame[labelIndex]
print(batterGradingDataFrame.head())
print(featureColumn)
# Apply Standard Scaler
scaler = StandardScaler()
x_scaled = scaler.fit_transform(x)
# Test Splitting & Random Seed
test_size = 0.2
random_seed = 42
# Split the data
x_train, x_test, y_train, y_test = train_test_split(
x_scaled, # Your input features (after scaling)
y, # Your target/label values
test_size=test_size, # 20% test, 80% train
random_state=random_seed, # Ensures reproducibility
stratify=y # Keep class distribution balanced in both sets
)
#Train model with classification model (random forest)
model = RandomForestClassifier(random_state=random_seed)
model.fit(x_train, y_train)
#Evaluate model (get the accuracy)
y_pred = model.predict(x_test)
print(classification_report(y_test, y_pred))
#Export the model for further use without training
joblib.dump(model, 'battery_model.joblib')
